- June 23, 2026Research
On efficient scaling of GNNs via IO-aware layer implementations
- February 13, 2026Research
GraphPFN: a graph foundation model pretrained on diverse synthetic graphs
- September 20, 2024Research
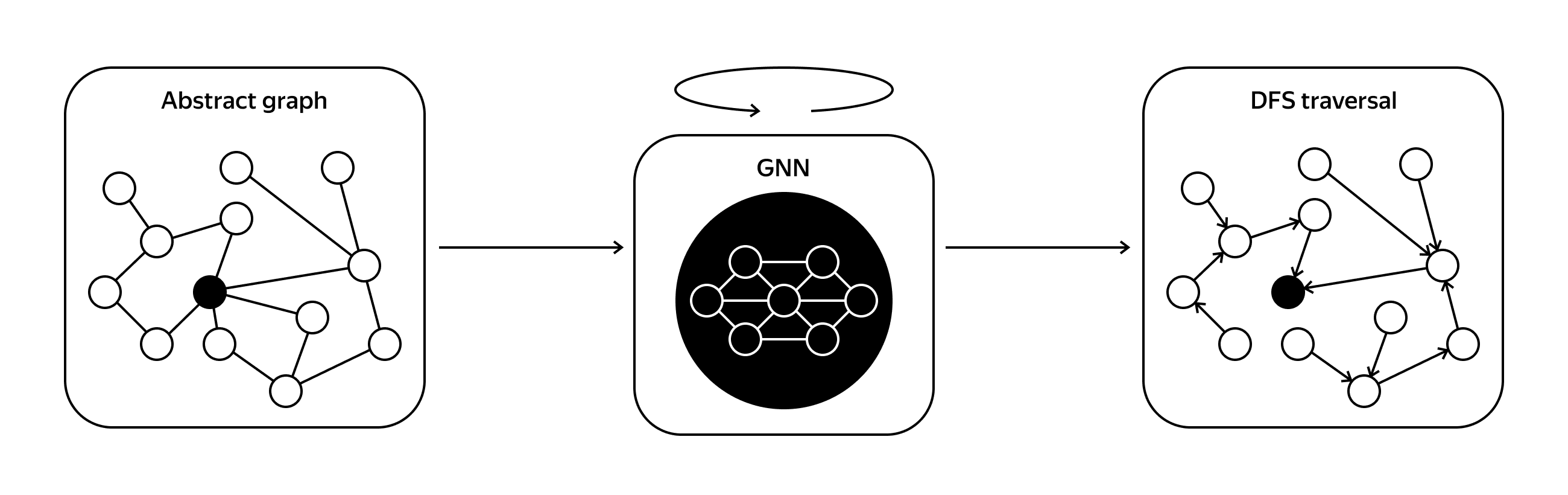
Discrete neural algorithmic reasoning
Graph machine learning
Graphs are a natural way to represent data from various domains such as social networks, molecules, text, code, etc. We develop and analyze algorithms for graph-structured data.

Posts
Publications
GraphPFN: A Prior-Data Fitted Graph Foundation Model
ICML, 2026Graph foundation models face several fundamental challenges including transferability across diverse domains and data scarcity, which calls into question the very feasibility of creating such models. However, despite similar challenges, the tabular domain has recently witnessed the emergence of the first successful foundation models such as TabPFN. These models are based on the prior-data fitted networks (PFN) framework, in which models are pretrained on carefully designed synthetic datasets to make predictions in an in-context learning setting. Recently, G2T-FM, a framework that converts graph node-level tasks into tabular tasks, has made the first step towards adopting PFNs for graphs, yet it is limited to hand-crafted features and was never pretrained on graph data. In this work, we make the next step by proposing GraphPFN, a PFN-based model designed and pretrained specifically for graph node-level tasks. Following the PFN framework, we first design a prior distribution of synthetic attributed graphs by using a novel combination of multi-level stochastic block models and a preferential attachment process for structure generation and graph-aware structured causal models for attribute generation. Then, we augment the tabular foundation model LimiX with attention-based graph neighborhood aggregation layers and train it on millions of synthetic graphs sampled from our prior. On diverse real-world graph datasets with node-level tasks, GraphPFN achieves state-of-the-art results in both in-context learning and finetuning regimes, outperforming G2T-FM, prior GFMs, and task-specific GNNs trained from scratch. More broadly, GraphPFN shows the potential of PFN-based models for building graph foundation models.
On Efficient Scaling of GNNs via IO-Aware Layers Implementations
ICML, 2026Graph Neural Networks (GNNs) are bottlenecked by sparse, irregular memory access. Popular frameworks such as DGL and PyTorch Geometric support general message passing, but complex layers often materialize edge-wise intermediates, increasing memory traffic and limiting scalability on large graphs. We take an I/O- and arithmeticintensity–centric view and show that widely used layers fall into three kernel families: SpMMbased convolutions, reduction-based aggregations, and attention-based layers (GATv2/Graph Transformer). For each family, we develop GPU kernels that reduce data movement, improve locality, and remain robust across realistic graphs. We also study graph reordering and find that its impact depends on the kernel mapping: it benefits neighbor-parallel (gather-dominated) kernels more consistently than feature-parallel designs. Empirically, our fused attention kernels reach up to 3.9× speedup for Graph Transformer (median 1.6×), with Tensor Core (block-sparse) variants up to 7.3× on locally dense graphs; for GATv2 we reach up to 8.5× speedup (median 2.0×) while reducing peak memory by up to 76× (median 6×). Our degree-aware reduction kernels achieve up to 10× speedup (median 2.6×). For SpMM-based layers, properly cached cuSPARSE achieves up to 8× speedup over DGL and outperforms evaluated custom baselines in the majority of evaluations. We release our implementations as drop-in replacements in our GitHub repository to support reproducible, hardware-aware GNN acceleration.
GraphLand: Evaluating Graph Machine Learning Models on Diverse Industrial Data
NeurIPS Datasets and Benchmarks, 2025Although data that can be naturally represented as graphs is widespread in real-world applications across diverse industries, popular graph ML benchmarks for node property prediction only cover a surprisingly narrow set of data domains, and graph neural networks (GNNs) are often evaluated on just a few academic citation networks. This issue is particularly pressing in light of the recent growing interest in designing graph foundation models. These models are supposed to be able to transfer to diverse graph datasets from different domains, and yet the proposed graph foundation models are often evaluated on a very limited set of datasets from narrow applications. To alleviate this issue, we introduce GraphLand: a benchmark of 14 diverse graph datasets for node property prediction from a range of different industrial applications. GraphLand allows evaluating graph ML models on a wide range of graphs with diverse sizes, structural characteristics, and feature sets, all in a unified setting. Further, GraphLand allows investigating such previously underexplored research questions as how realistic temporal distributional shifts under transductive and inductive settings influence graph ML model performance. To mimic realistic industrial settings, we use GraphLand to compare GNNs with gradient-boosted decision trees (GBDT) models that are popular in industrial applications and show that GBDTs provided with additional graph-based input features can sometimes be very strong baselines. Further, we evaluate currently available general-purpose graph foundation models and find that they fail to produce competitive results on our proposed datasets.
Datasets
GraphLand
GraphLand is a benchmark of 14 diverse graph datasets for node property prediction from a range of different industrial applications. GraphLand allows evaluating graph ML models on a wide range of graphs with diverse sizes, structural characteristics, and feature sets, all in a unified setting. Further, GraphLand allows investigating such previously underexplored research questions as how realistic temporal distributional shifts under transductive and inductive settings influence graph ML model performance.
Heterophilous graph datasets
A graph dataset is called heterophilous if nodes prefer to connect to other nodes that are not similar to them. For example, in financial transaction networks, fraudsters often perform transactions with non-fraudulent users, and in dating networks, most connections are between people of opposite genders. Learning under heterophily is an important subfield of graph ML. Thus, having diverse and reliable benchmarks is essential.
We propose a benchmark of five diverse heterophilous graphs that come from different domains and exhibit a variety of structural properties. Our benchmark includes a word dependency graph Roman-empire, a product co-purchasing network Amazon-ratings, a synthetic graph emulating the minesweeper game Minesweeper, a crowdsourcing platform worker network Tolokers, and a question-answering website interaction network Questions.