In our paper [1], we argue that there are several disadvantages of using hints and investigate whether it is possible to train a competitive model using only input-output pairs.
First, we highlight some disadvantages of hint usage:
- Hints need to be carefully designed separately for each task and algorithm. Moreover, various model architectures may benefit from differently designed hints.
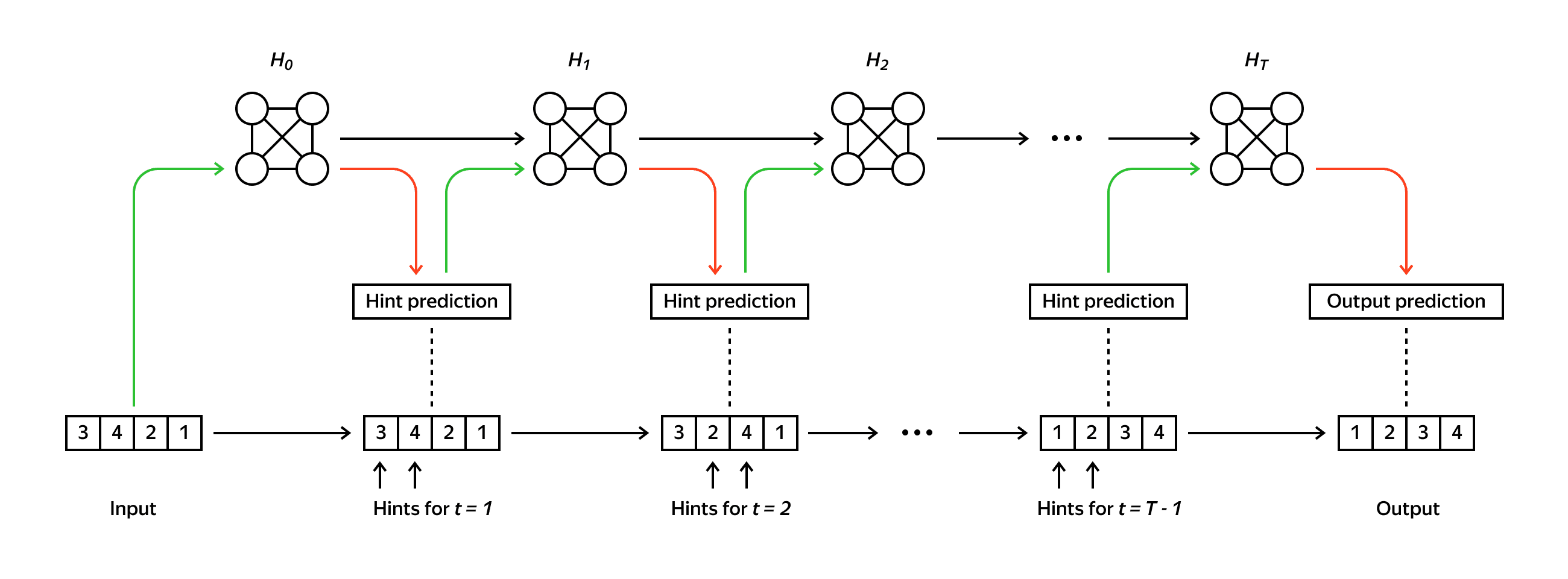
- Hints force the model to follow a particular trajectory. While this may help the interpretability and generalization of the trained model, following the algorithm’s steps can be suboptimal for a neural network architecture. For instance, it may force the model to learn sequential steps, while parallel processing can be preferable.
- A model trained with direct supervision on hints does not necessarily capture the dependencies between hints and the output of the algorithm. In other words, the model potentially can consider the hint sequence as a separate task (we refer to Section 3 of our paper).
- If a model is not restricted to a particular trajectory, it may potentially learn new ways to solve the problem, and thus by interpreting its computations, we may get new insights into the algorithms’ design.
To design our alternative approach, we make an observation that helps us to combine the advantages of learning algorithms only from input-output pairs with inductive bias improving the size generalization capabilities of the models.
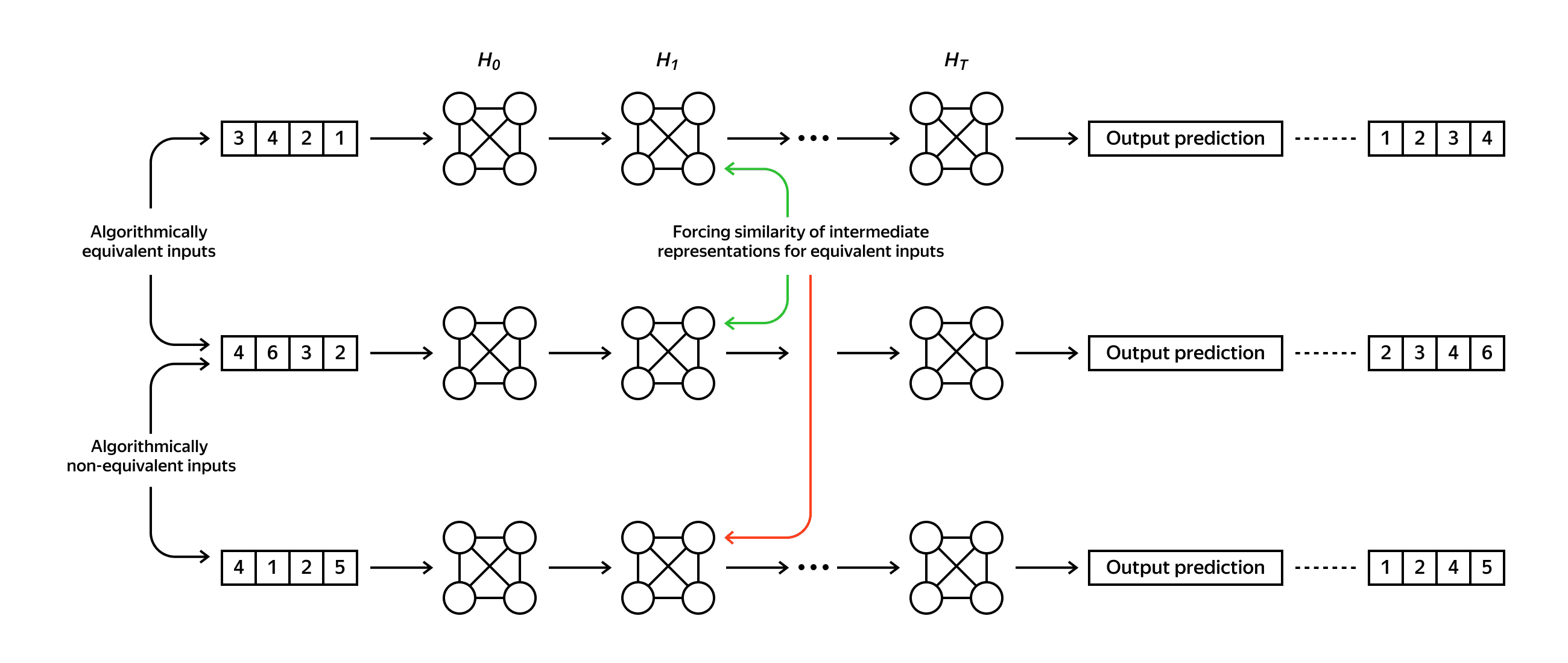
We note that the underlying combinatorial structure of some tasks allows us to describe the properties of the desired algorithm. Such properties can reduce the search space of the model while remaining in the wide range of possible algorithms, which can solve the given problem. For example, any comparison sort has the same trajectory for any pair of arrays with the same relative order of its elements. Given that, we can construct such a pair of different inputs that every step of any comparison sort algorithm is the same for both inputs. A less trivial example is the minimum spanning tree problem. A wide range of algorithms have the same execution trajectory on graphs with fixed topology (graph structure) and different weights on edges if the relative order of the corresponding edge weights is the same.
Forcing a model to act similarly on algorithmically equivalent inputs gives the model an additional signal about the problem without providing any constraints on computations that the model needs to follow. We can do it with classic contrastive learning techniques.