In reliable decision-making systems based on machine learning, models should comprise several important properties that allow users to rely on their predictions. One of them is robustness, the ability of a model to handle distributional shifts and provide high predictive performance even when the features of test inputs differ from those encountered during the training stage. If this property is hard to satisfy, a model should at least signal potential problems by providing some measure of uncertainty in its predictions. It then can be used to detect shifted samples and delegate the processing task to a human expert.
In node-level problems of graph learning, distributional shifts can be especially complex since samples are connected and depend on each other. It means that a distributional shift may occur not only in the features of nodes but also in the structure of an underlying network. In practice, these changes may happen simultaneously, creating a great challenge for Graph Neural Networks (GNNs) that use node features and graph structure to make predictions.
To evaluate the performance of graph models, it is essential to test them on diverse and meaningful distributional shifts. While some graph datasets may come with natural distributional shifts (e.g., based on timestamps) [1], such shifts are rarely available. Most graph benchmarks that artificially create distributional shifts for node-level problems, such as the Graph OOD benchmark [2], focus mainly on node features. At the same time, structural properties are also important for graph problems. The main issue in considering only the node features of graph datasets is that one has to perform screening over the available features to understand which can be used to split the data. Each new dataset requires a different approach and possibly special expert knowledge to create a node-level distributional shift. In contrast, the graph structure is the only common modality of different graph datasets that can be exploited similarly to model meaningful distributional shifts.
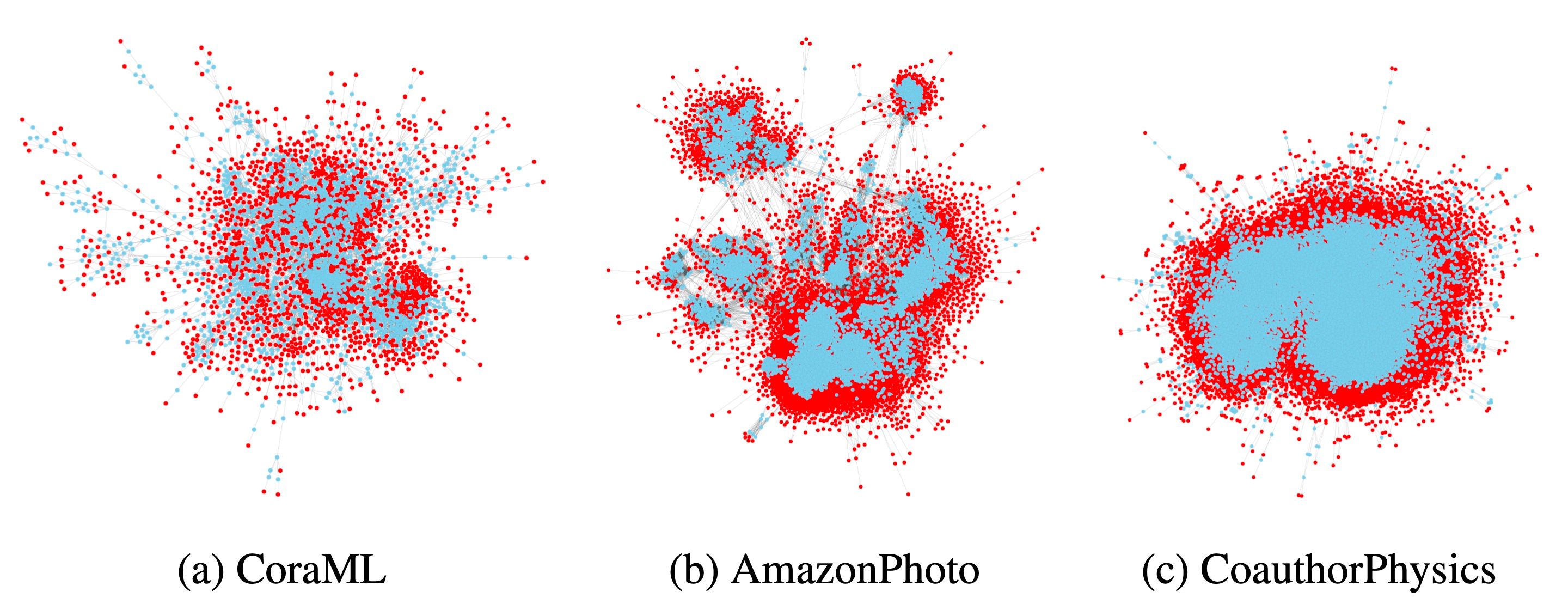
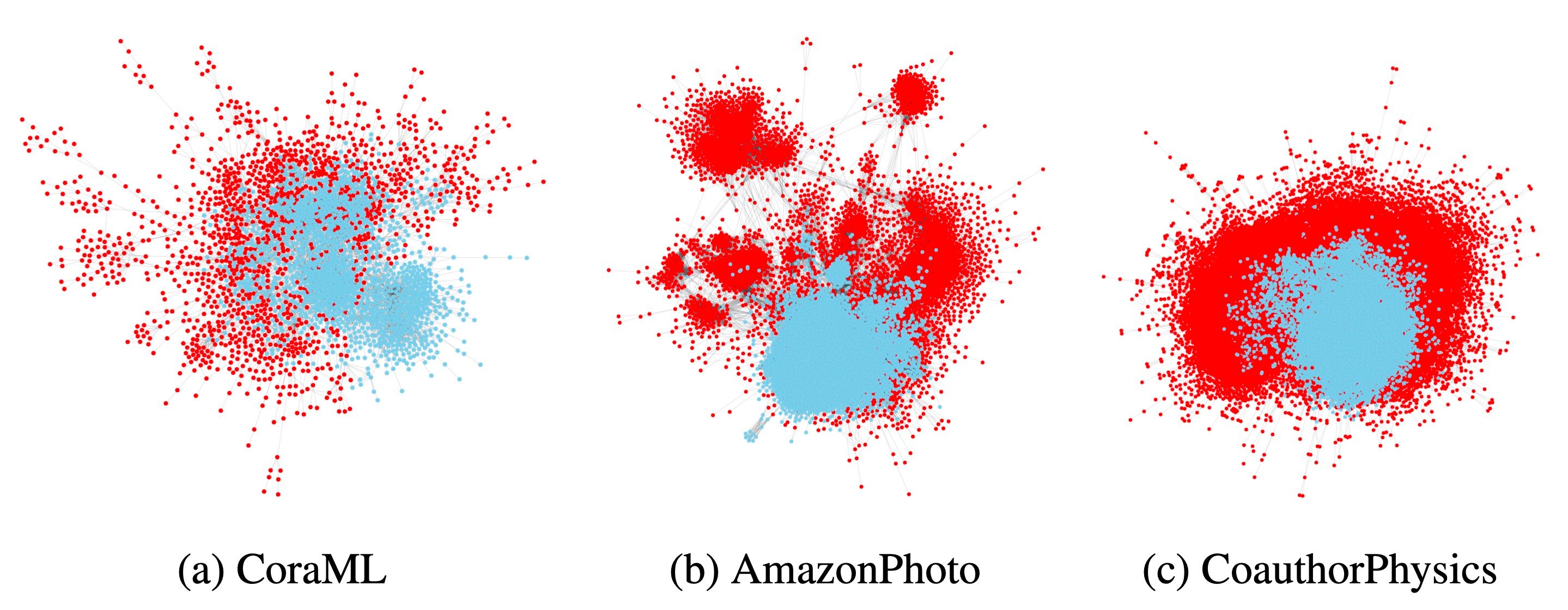
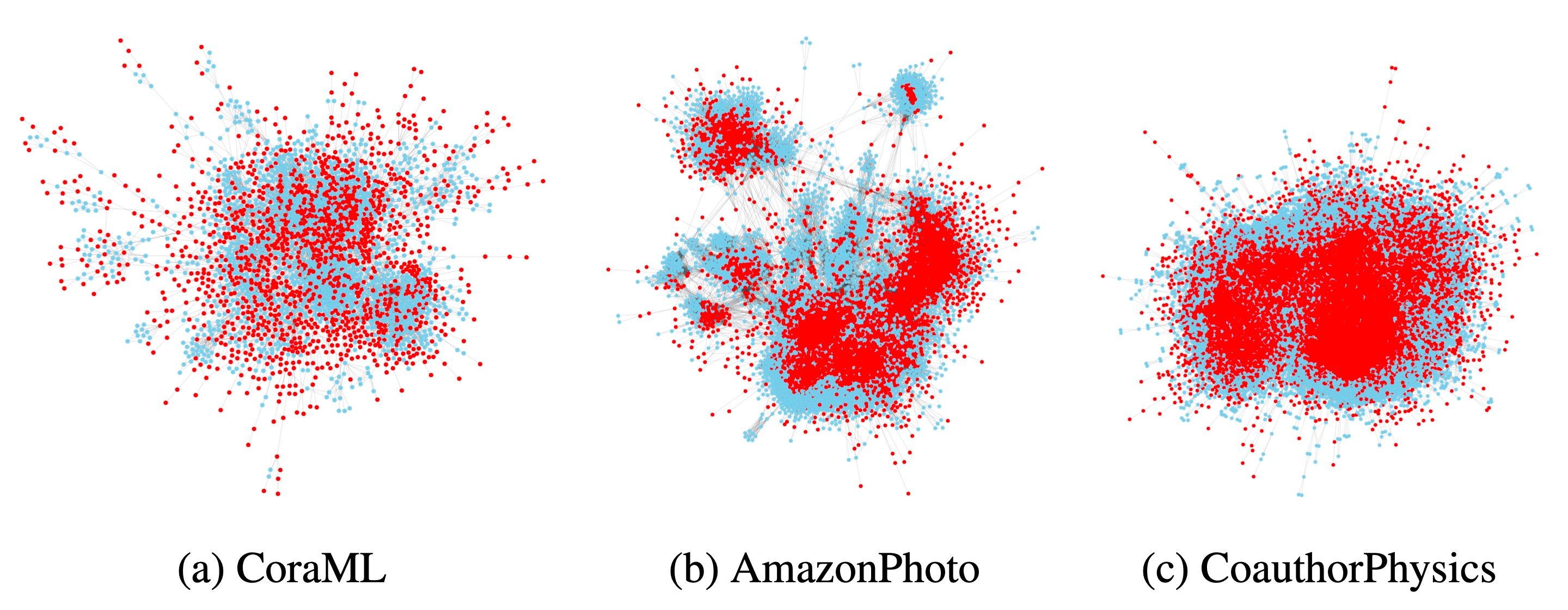
We propose [3] a general approach for inducing diverse distributional shifts based on graph structure. In particular, we compute an arbitrary node-level characteristic that reflects some structural property of nodes. Then, we sort all nodes in ascending order of this characteristic and split them into different subsets — those with the smallest values are considered to be in-distribution (ID), while the remaining ones are out-of-distribution (OOD). As a result, we obtain a graph-based distributional shift where ID and OOD nodes have different structural properties.
Using this approach, we create data splits according to several structural node properties. In particular, our popularity-based shift models the situations when the training set consists of more popular (or important) items. This may happen if labels are assigned first to the most popular nodes that are considered to be particularly important for good prediction. However, when applying the model, making accurate predictions on less popular items is essential. Our popularity-based shift is based on PageRank, a well-known measure of node importance in a graph.