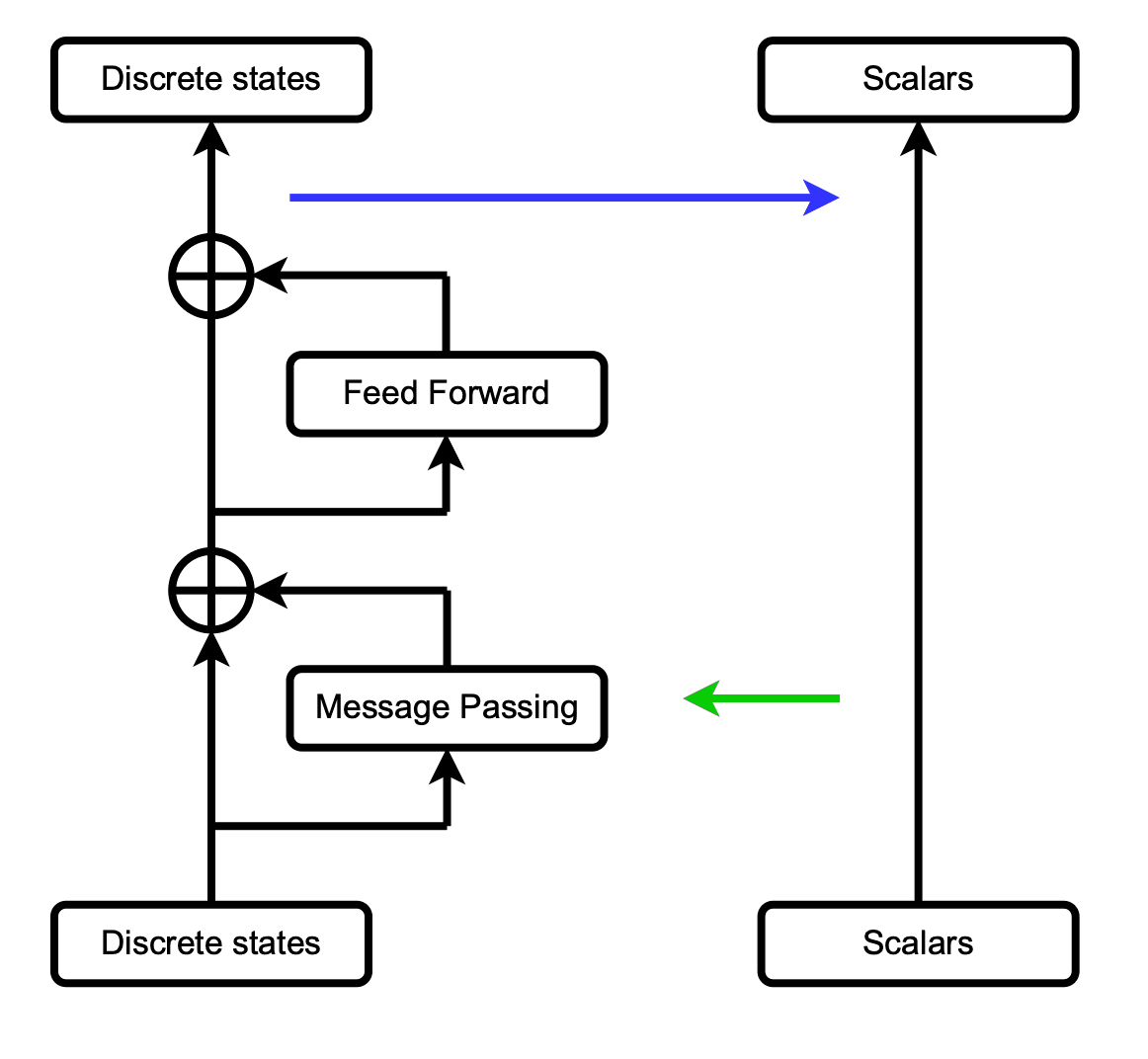
An illustration of the proposed separation between discrete and continuous data flows. Scalars can only affect the attention weights (Green) and can be modified with actions via ScalarUpdate (Blue).
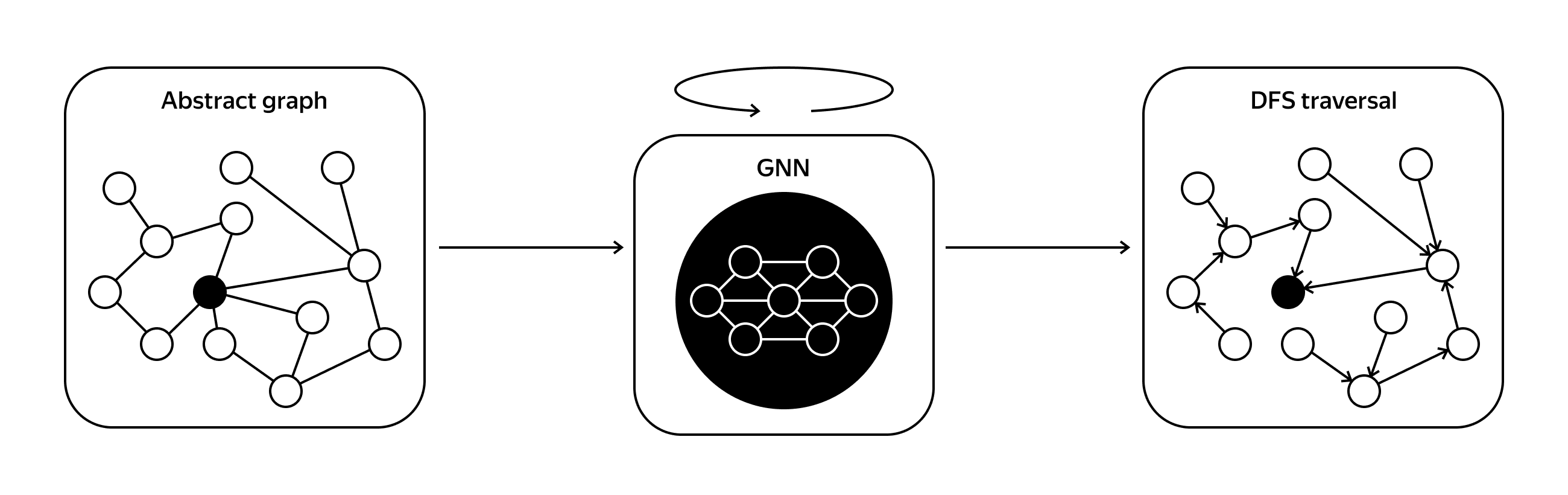
For the BFS problem, we are given a graph and a starting node. For each node, we predict its parent in the BFS tree.
For the BFS problem, we use two node states (Discovered, NotDiscovered) and two edge states (Pointer, NotAPointer). At the initial step, only the starting node has the state Discovered.
For the BFS problem, we use positional information to break ties in traversal order. Each node chooses as a parent the neighbor from the previous distance layer with the smallest index. As graphs can be arbitrarily large, operating with positional information would require infinite precision, so we propose not to discretize it.
For the BFS problem, the proposed selector allows us to exactly perform computations like “for unvisited node select the best visited neighbor”.
For the BFS problem, we can inspect the model and verify that the attention of Visited→Unvisited dominates the attention of Unvisited→Unvisited, so, at each step, each unvisited node will receive the message from a visited neighbor if such exists, or from an unvisited node otherwise. Then, by passing the corresponding states to the MLP after the message passing, we can check if the receiver node becomes visited or not regarding the received message, and so on.