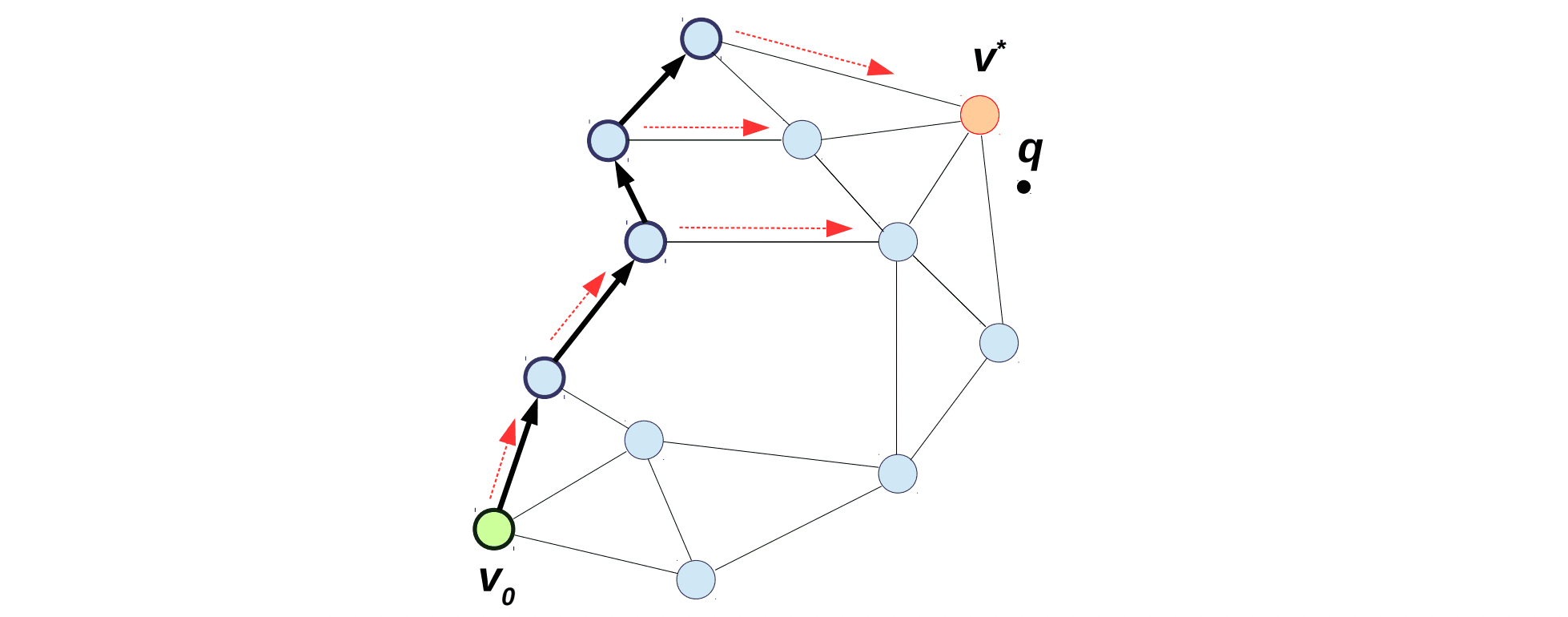
While graph-based approaches to NNS are widely used in practice, little is known about their theoretical guarantees. To make the first step in this direction, we study the convergence and complexity of graph-based NNS, assuming that a dataset is uniformly distributed on a $d$-dimensional sphere. Under this assumption, there are two principally different scenarios: low-dimensional (dense) if $d \ll \log n$ and high-dimensional (sparse) if $d \gg \log n$.
The dense setting is much easier for all NNS methods: it is often possible to guarantee that the nearest neighbor is found in sublinear time. Conversely, the sparse setting is much more challenging: usually, the complexity of NNS scales exponentially with the dimension, which becomes infeasible for $d \gg \log n$. Therefore, the problem is often relaxed to approximate NNS, where we need to find an element at a distance at most $c$ times larger than the distance to the nearest element, $c>1$.
In fact, real datasets are never uniformly distributed, and they usually have low intrinsic dimension while being embedded into a high-dimensional space. However, theoretical analysis of the uniform setup allows one to get intuition on how graph-based approaches are expected to work depending on the intrinsic dimensionality of data.
In [15], we first analyze the convergence and complexity of greedy search over k-NN graphs. In particular, for the sparse setting, the query time for $c$-approximate NNS is $n^{\varphi}$, where the value $\varphi < 1$ depends on the approximation factor $c$ (larger values of $c$ lead to faster but less accurate NNS).
For the dense setting, we show that the query time for the exact NNS grows as $2^{d/2}n^{1/d}$. Here $2^{d/2}$ corresponds to the complexity of one step of graph-based descent and $n^{1/d}$ to the number of steps. If $d$ is small ($d < \sqrt{\log n}$), the number of steps $n^{1/d}$ dominates the complexity of one step $2^{d/2}$. Fortunately, the number of steps can provably be reduced to $\log n$ via so-called long edges. We show that long edges should be carefully added to achieve such logarithmic complexity: roughly speaking, the probability of adding an edge to $k$-th closest element should be proportional to $1/k$.