
Vehicle Motion Prediction
The problem of motion prediction is one of the most important problems in the autonomous driving domain. A self-driving vehicle, like any vehicle, needs a certain amount of time to change its speed, and sudden changes in speed and acceleration may be uncomfortable or even dangerous for passengers. To ensure a safe and comfortable ride, the motion planning module must predict where other vehicles might end up in a few seconds.
The problem is complicated because it involves inherent uncertainty — we can’t always guess the intentions of agents such as pedestrians and other drivers, and this uncertainty must be precisely quantified in order for the planning module to make the right decision.
Our world is diverse, so driving conditions can vary significantly from location to location. Therefore, autonomous driving technology companies face a distributional shift when driving through new locations, or even on a new route in a familiar location. It is essential to transfer as much knowledge as possible from the old locations to the new ones. It is also critical for a planning model to recognize when the transferred knowledge is insufficient upon encountering unseen data, and to acknowledge that there is a risk of unpredictable and unsafe behavior. When this happens and a model’s predictive uncertainty reaches a certain threshold, the vehicle would need to switch to a more cautious driving mode or ask for additional human input.

Data & Task
Data for this task uses a vehicle motion prediction dataset collected by the Yandex Self-Driving Group (SDG). Each scene in the dataset is 10 seconds long and is divided into two 5-second parts: 5 seconds of context and 5 seconds of prediction targets. The scenes include information about dynamic objects and a map. Vehicles are described by position, velocity, linear acceleration, and orientation.
Data is sampled with 5Hz frequency using the SDG perception stack. The map includes lane information (e.g., traffic direction, priority, speed limit), road boundaries, crosswalks, and traffic light states.
Training, development, and evaluation data for the competition will be partitioned by location. The training data, in-domain development and evaluation data will be taken from Moscow. Distributionally shifted development data will be taken from Skolkovo, Modiin, and Tel Aviv. Distributionally shifted evaluation data will be taken from Innopolis and Ann Arbor.

In addition, we will remove all examples of precipitation from the in-domain training, development, and evaluation sets, while distributionally shifted data will feature precipitation. Ground truth labels and metadata is provided only for training and development data.
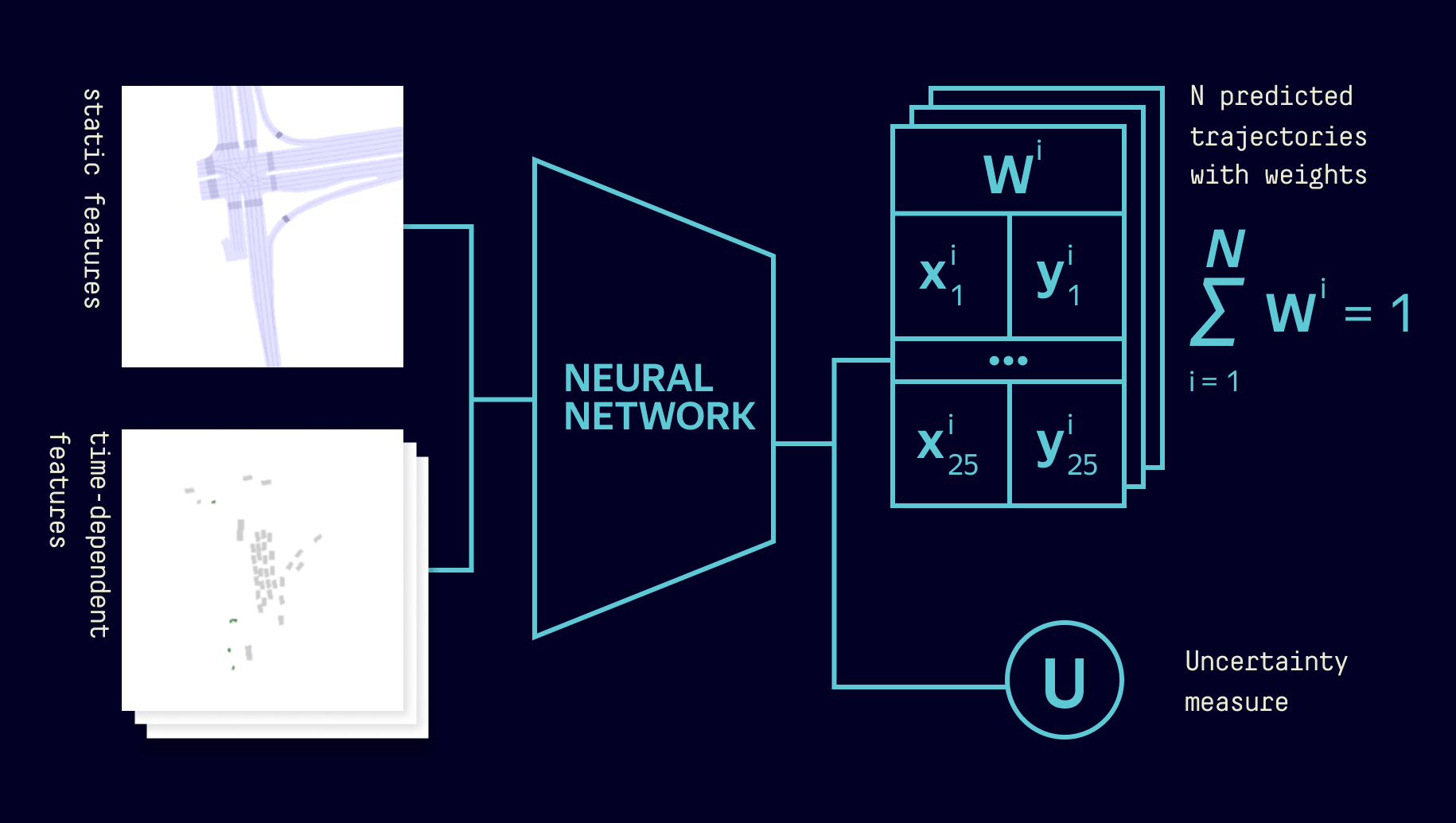
The goal is to predict for each vehicle 5s trajectories sampled at 5Hz, for a total of 25 distinct x-y coordinates into the future.

Metrics
In the vehicle motion prediction task we will consider the confidence-weighted and minimum Average Displacement Error (wADE / minADE), the confidence-weighted and minimum Final Displacement Error (wFDE / minFDE), and the corrected Negative Log-Likelihood across all predicted trajectories as error metrics. If your model returns more than a single trajectory per object, you must submit confidence scores for each trajectory which are non-negative and sum to one.
To assess the joint quality of uncertainty estimates and robustness, we will use the area under an error retention curve (R-AUC) as the competition score. Here, predictions for a particular input are replaced by ground-truth targets in order of descending uncertainty. This decreases the error, measured in terms of corrected Negative Log-Likelihood (cNLL). Area under the curve can be reduced either by improving performance or by the uncertainty-based rank-ordering, so that bigger errors are replaced first. This will be the target metric used to rank participants’ submissions to the vehicle motion prediction track. All metrics will be evaluated jointly on in-domain and shifted data. We have replaced wADE with cNLL for error computation due to poor modelling of multi-modality — please see our paper for details.
For the participants’ benefit and to obtain greater insights we provide additional metrics for assessing models. Shifted-data detection performance will be evaluated using ROC-AUC. We also introduce two F1-based metrics, called F1-AUC and F1 @ 95%, which jointly evaluate the quality of uncertainty and predictions. These are also computed using cNLL as the error metric. Finally, we also display the area under the wADE rejection curve, which was the previous score metric. These metrics do not affect leaderboard ranking.
Further details of all metrics are provided on GitHub and in our paper.
Leaderboard
| Rank | Teamname/ username | Method Name | Score (R-AUC cNLL) | cNLL | wADE | wFDE | minADE | minFDE | R-AUC wADE | ROC-AUC (%) | AUC-F1 | F1 @ 95% | Date Submitted |
|---|
