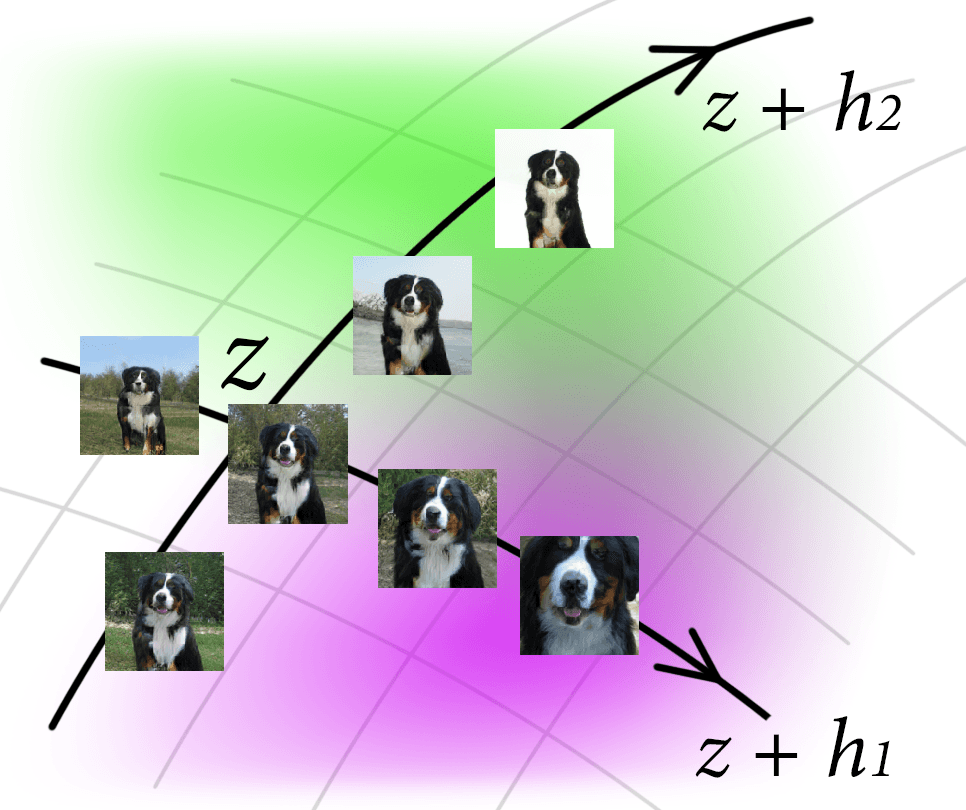
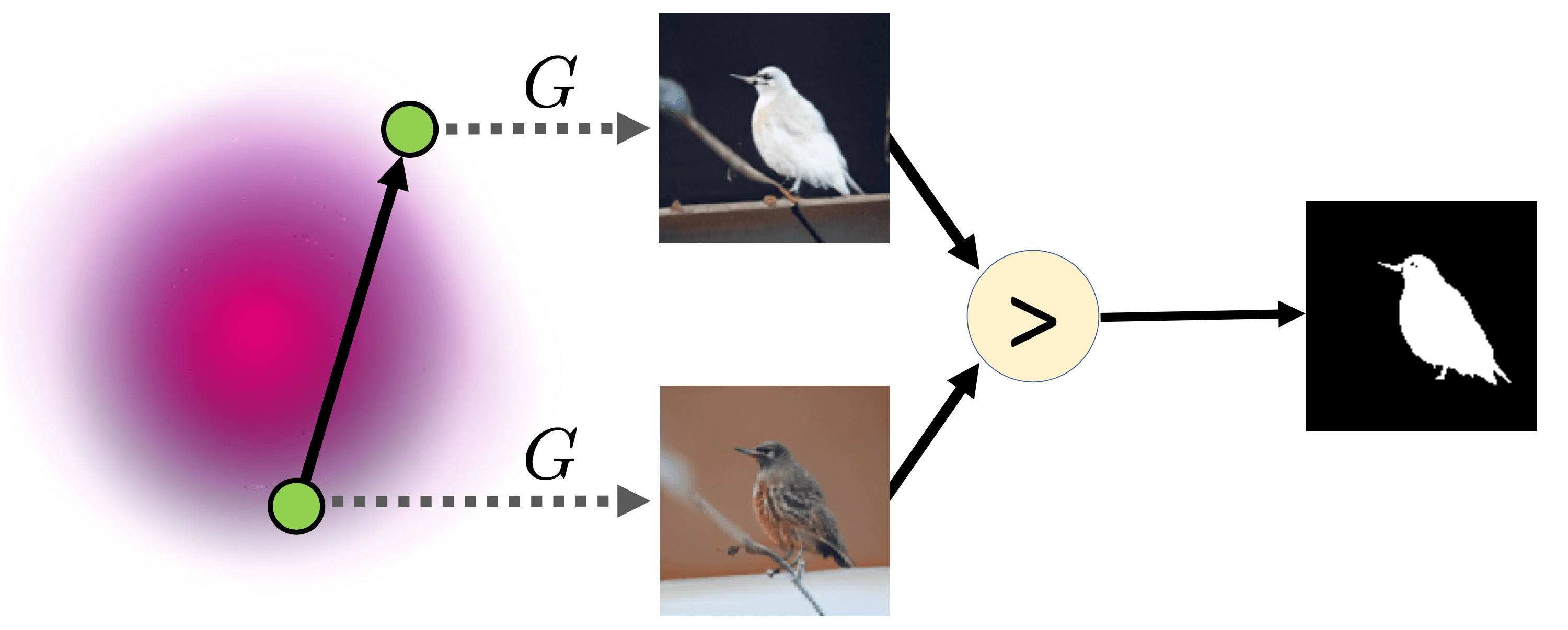
By studying latent manipulations, we found that it is possible to find a latent shift when the transformation of images becomes semantically loaded. For instance, the wheels of cars become bigger, people begin to smile, summer turns into winter, etc.
Before, researchers trained models in supervised mode, with markup simplifying transformations. The supervised setup allowed us to find merely what we expected to see. But once we follow an unsupervised setup, we let a model reveal its manipulations. This work was the first to adress the latent manipulations search in a fully unsupervised manner.