
SpecExec: Massively Parallel Speculative Decoding for Interactive LLM Inference on Consumer Devices
We introduce SpecExec, a speculative decoding method that delivers up to 20 tokens per iteration and up to 15x speedups in offloading settings. This enables usable LLM inference speeds for users with limited GPU VRAM sizes, who have had to use offloading or settle for lower quality models until now.
Intro
As large language models (LLMs) like LLaMA and Mistral gain widespread adoption, data science enthusiasts and practitioners are looking for ways to run them faster and with lower hardware requirements. One alternative for users with less capable hardware is to use offloading, a method where only a few layers are initially loaded onto the GPU and the rest are kept in RAM / on SSD and loaded to the GPU sequentially. Naturally, it is quite slow since such loading for Llama-2-70B in 16-bit can take over 5 seconds even with PCIe gen 4 bus.
Speculative decoding
To accelerate generation in an offloading setup, one can use speculative decoding. This approach typically involves a much smaller “draft” model for fast generation of proposed continuation token series (or trees of such series). Once the proposed continuations are generated, the main “target” model validates them and chooses to accept one or none, using a stochastic sampling algorithm.
The performance of speculative decoding algorithms is measured in terms of number of tokens generated per iteration i.e., the number of tokens accepted by the target model based on the draft model proposals. Combined with the model timings, this metric defines the resulting performance of the algorithm.
SpecExec method
Our method named SpecExec (after Speculative Execution) was designed to get best speculative decoding performance in such situations. SpecExec takes the most probable tokens continuation from the draft model to build a “cache” tree for the target model, which then gets validated by the target model in a single pass. It allows arbitrary shapes of draft token trees and works with greedy, nucleus or any other sampling function.
The method works especially well because of the high spikiness of token probability distributions in modern large LLMs. As shown in the picture below, the top-1 token in the Llama-2-70B model contains almost 90%+ of probability space on average and a capable companion model, like Llama-2-7B, covers almost 90% of it with a mere four tokens. This means that a few top predictions by the draft model can be considered an execution cache for the target model with a very high hit likelihood.
Since our method performs best with a rather capable draft model (Llama2-7B for Llama2-70B target), it shows the most impressive results in offloading settings, where the time budget for the speculation phase can be rather large.
SpecExec Performance
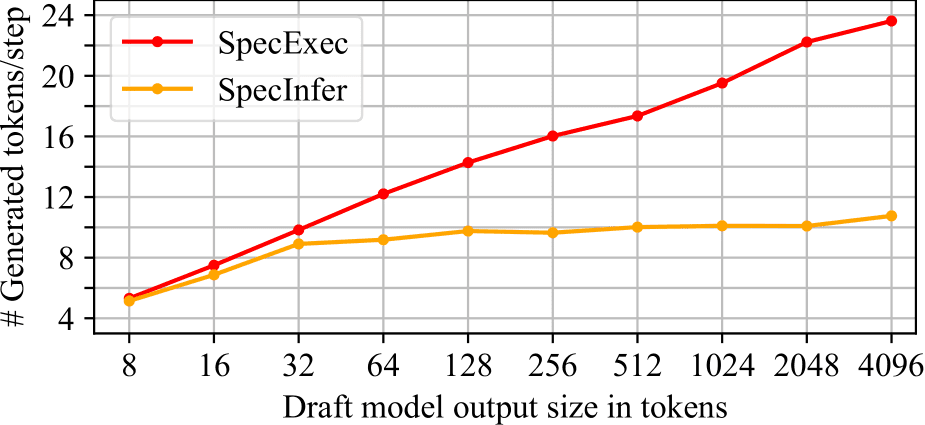
We compare SpecExec performance with the popular SpecInfer speculative decoding method. With low token budgets performance in terms of generated tokens per step is close. As the budget grows into hundreds and thousands, Specinfer stops showing improvements while SpecExec shows over 20 generated tokens per step with budgets beyond 1K. The chart above is based the MTBench dataset and Llama2-7/70 chat models.
The table below compares SpecExec’s performance in offloading settings with SpecInfer, a popular speculative decoding method introduced in 2023. While the latter shows impressive speedups, our method more than doubles its performance both in speed and in accepted token counts.
| Draft / Target models | Dataset | Temperature | Method | Budget | Generation rate | Speed, tok/s | Speedup |
|---|---|---|---|---|---|---|---|
Llama2-7b / 70b
|
OAsst
| 0.6 | SX | 2048 | 20.60 | 3.12 | 18.7x |
| 0.6 | SI | 1024 | 8.41 | 1.34 | 8.0x | ||
| 0 | SX | 1024 | 18.8 | 2.74 | 16.4x | ||
| 0 | SI | 1024 | 7.86 | 1.18 | 7.1x | ||
| Llama2-7b / 70b GPTQ | OAsst | 0.6 | SX | 128 | 12.10 | 6.02 | 8.9x |
| 0 | SX | 256 | 13.43 | 6.17 | 9.1x | ||
| Mistral-7b / Mixtral-8x7b-GPTQ | OAsst | 0.6 | SX | 256 | 12.38 | 3.58 | 3.5x |
| Llama3-8b / 70b | 0.6 | SX | 1024 | 18.88 | 2.62 | 15.6x | |
| Llama3-8b / 70b | MTBench | 0.6 | SX | 1024 | 18.16 | 2.79 | 16.6x |
| 0 | SX | 2048 | 21.58 | 2.94 | 17.5x |
SpecExec can speed up LLM inference for various types of hardware. In addition to researcher-grade A100, we evaluated SpecExec with consumer GPUS ranging from 2080Ti to 4090. The results below were achieved with a quantized model that may fit the RAM of consumer grade computers. Note that speedup ranges from 4.6x to 10.6x, allowing generation speed in 3-6 tokens/s range.
| GPU | Draft model | Budget | Gen. rate | Speed, tok/s | Speedup |
|---|---|---|---|---|---|
| RTX 4090 | Llama2-7b GPTQ | 256 | 13.46 | 5.66 | 8.3x |
| RTX 4060 | Llama2-7b GPTQ | 128 | 9.70 | 3.28 | 4.6x |
| RTX 3090 | Llama2-7b GPTQ | 256 | 14.3 | 3.68 | 10.6x |
| RTX 2080Ti | ShearedLlama-1.3B | 128 | 7.34 | 1.86 | 6.1x |
We evaluated SpecExec with LLMs mainly with Llama family models, but believe that the results can be applied to other model families.
SpecExec represents a significant advancement in running large language models on consumer hardware. By leveraging high spikiness in token probability distributions and a capable draft model, it achieves impressive speedups and efficient token generation. This method not only democratizes access to powerful LLMs but also ensures high-quality inference is within reach for a broader audience.
Whether you are a researcher looking to maximize your hardware’s potential or a developer aiming to integrate powerful language models into your applications, SpecExec offers a robust, scalable, and efficient solution.