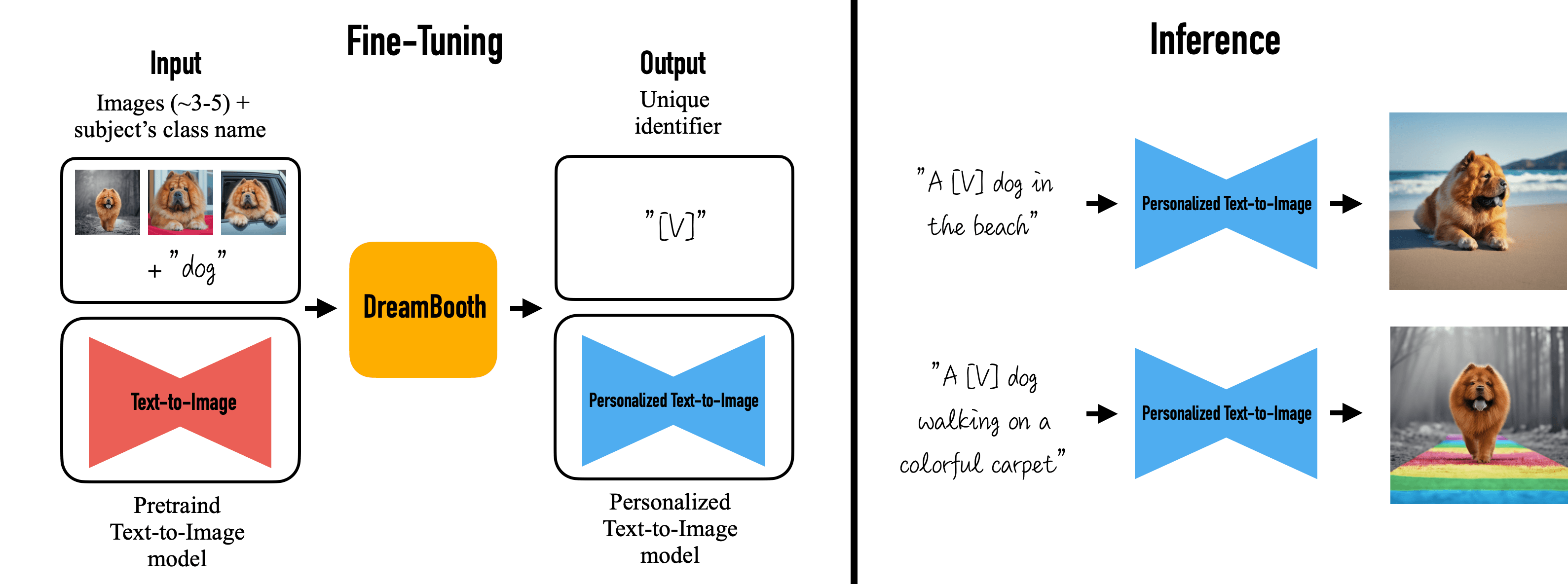
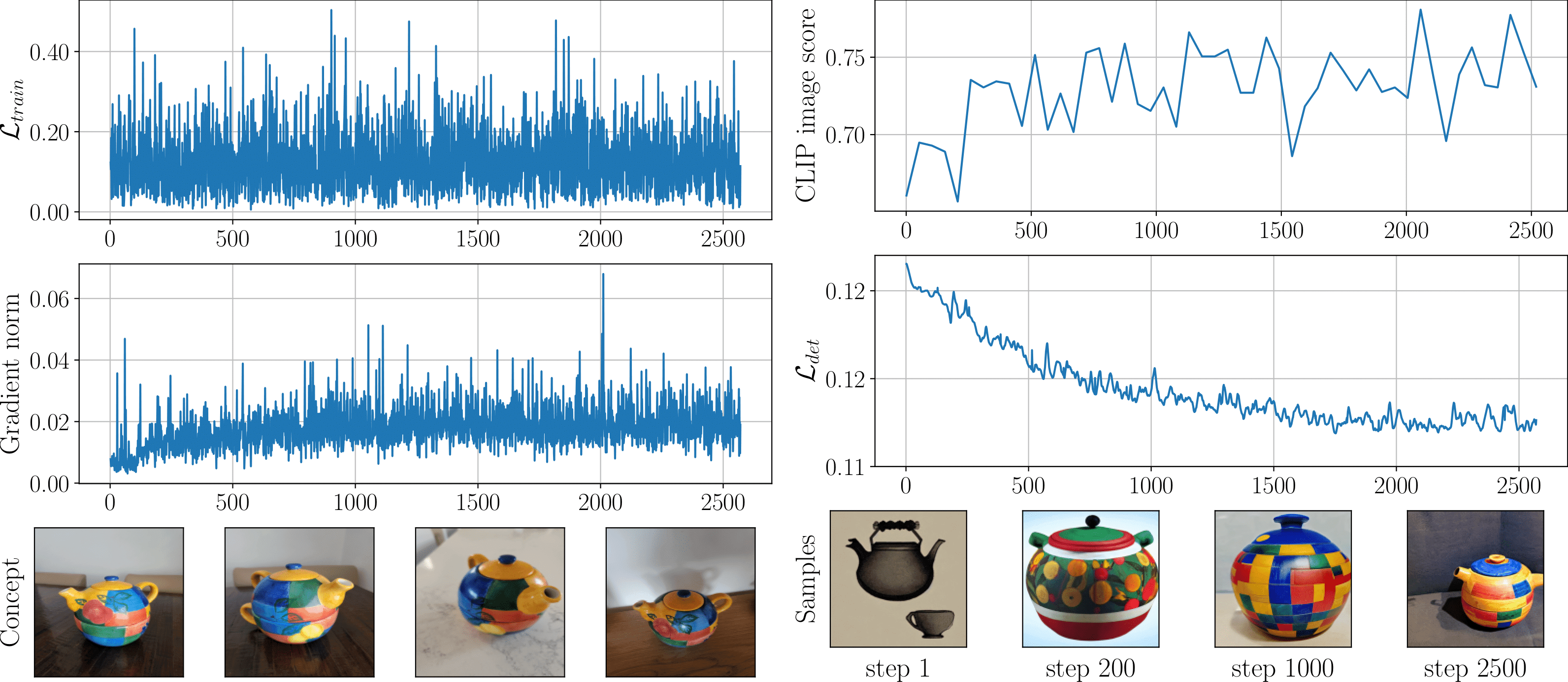
To evaluate the quality of customized models, we identified three characteristics: identity preservation, reconstruction ability, and unseen prompt alignment. To assess the first two, we compute CLIP image-to-image similarity between train/validation generated images and reference images. We named these metrics Train CLIP img and Val CLIP img respectively. To evaluate the latest quality, we use CLIP image-to-text similarity between validation images and prompts; we called this metric Val CLIP txt.
Our experiments were conducted on datasets provided by the authors of all three customization methods (48 concepts in total). Aggregated results for each approach are shown in the table below. We compare our approach with several baselines: the original training setup (Baseline), CLIP-based early stopping (CLIP-s), and a baseline with a fixed number of steps equal to average CLIP-s iterations (Few Iters). We observed that DVAR is more efficient than Baseline and CLIP-s in terms of overall runtime. An additional advantage of DVAR over Few Iters is its adaptability because not all concepts are equally easy to learn.