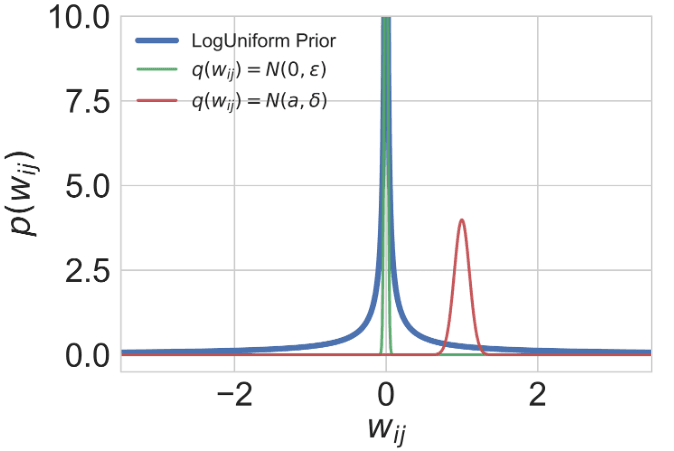
Yandex at ICML 2017: Variational Dropout Sparsifies Deep Neural Networks
Last week, Sydney, Australia hosted 34th International Conference on Machine Learning (ICML 2017), one of a few major machine learning conferences. Yandex team presented the result of the joint research project between Yandex, Skolkovo Institute of Science and Technology and National Research University Higher School of Economics. In our paper “Variational Dropout Sparsifies Deep Neural Networks”, we introduced Sparse Variational Dropout, a simple yet effective technique for sparsification of neural networks.
In practice Sparse VD leads to extremely high compression levels both in fully-connected and convolutional layers. It and allows us to reduce the number of parameters up to 280 times on LeNet architectures and up to 68 times on VGG-like networks with almost no decrease in accuracy.
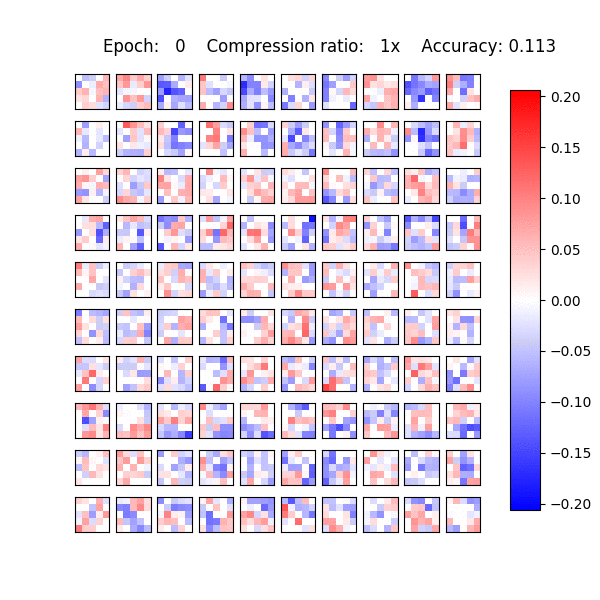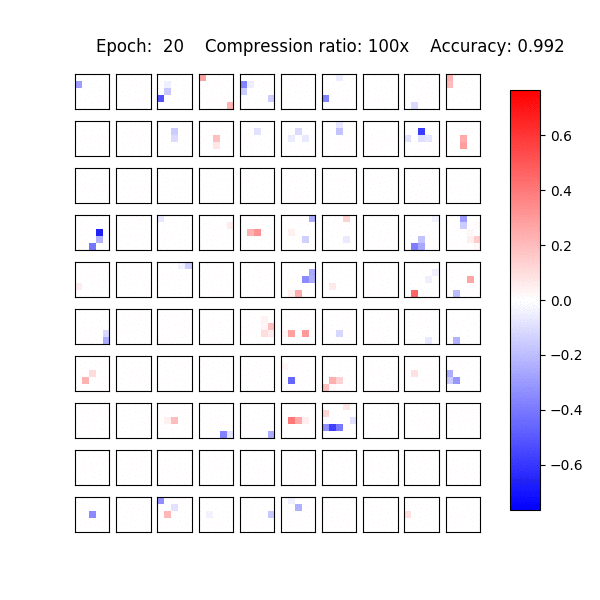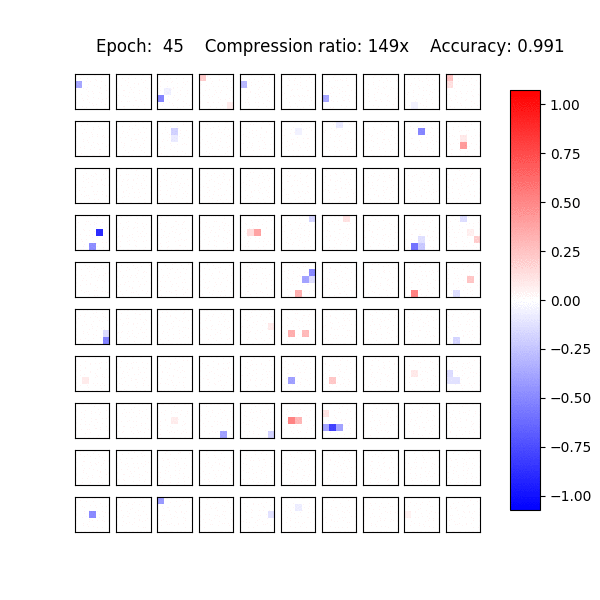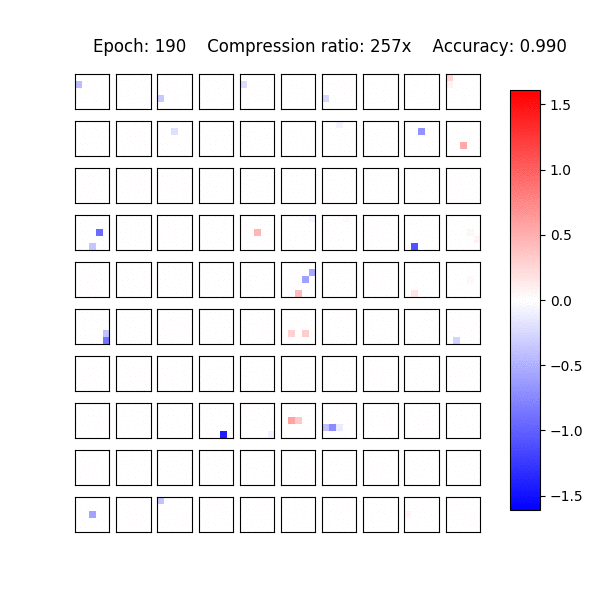
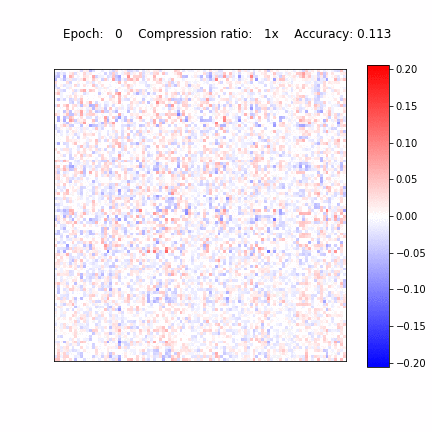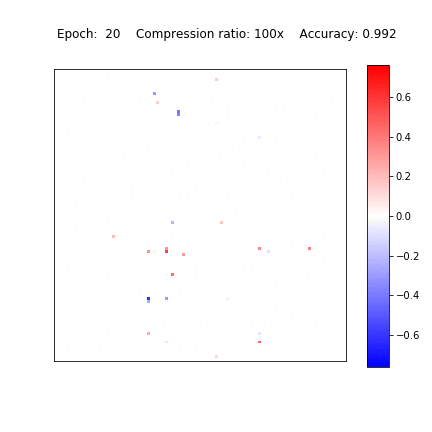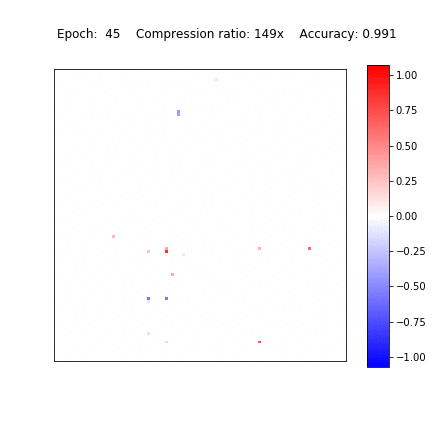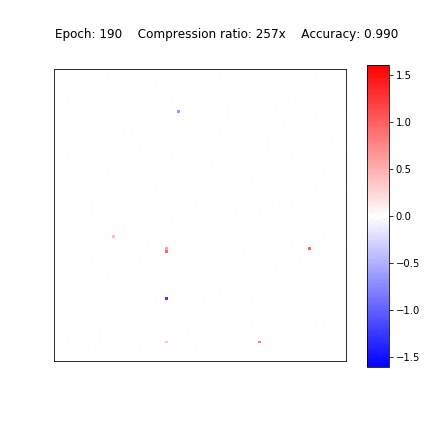
Recently, it was shown that the CNNs are capable of memorizing the data even with random labeling. The standard dropout as well as other regularization techniques did not prevent this behaviour. Following that work, we also experimented with the random labeling of data. Most existing regularization techniques do not help in this case. However, Sparse Variational Dropout decides to remove all weights of the neural network and yield a constant prediction. This way Sparse VD provides the simplest possible architecture that performs the best on the testing set.

Sparse Variational Dropout is a novel state-of-the art method for sparsification of Deep Neural Networks. It can be used for compression of existing neural networks, for optimal architecture learning and for effective regularization.
The source code is available at our Github page https://github.com/ars-ashuha/variational-dropout-sparsifies-dnn.