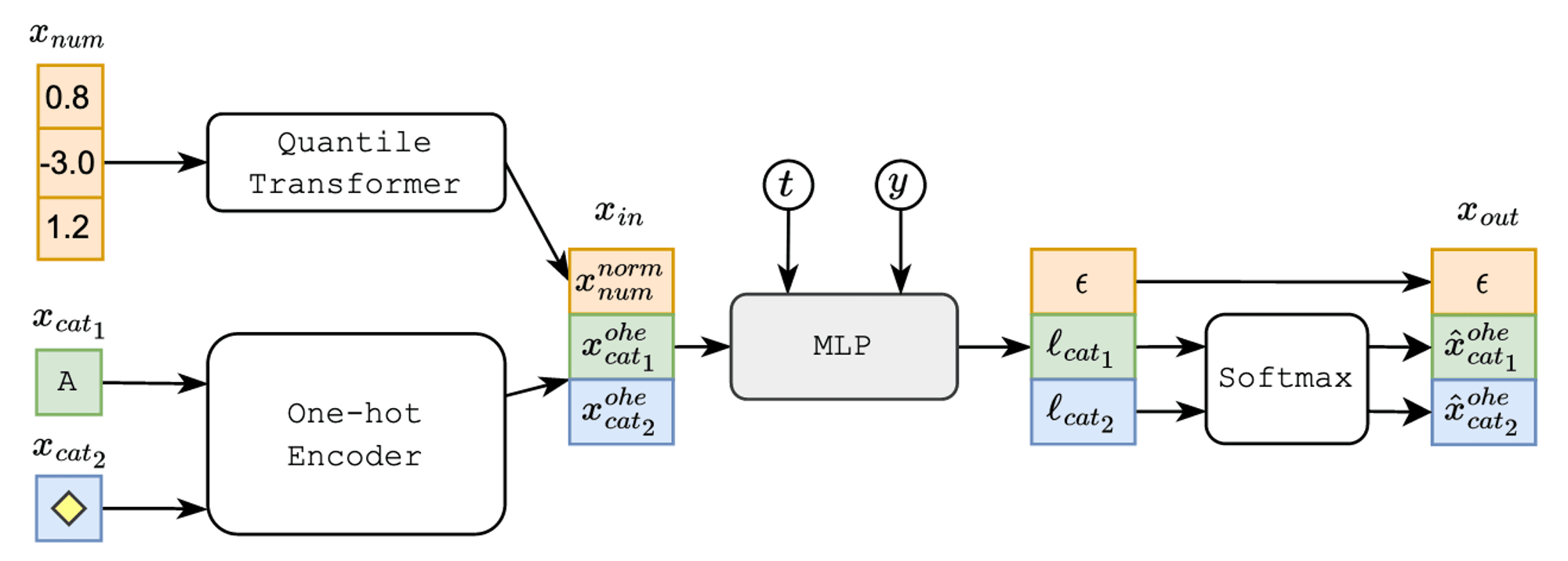
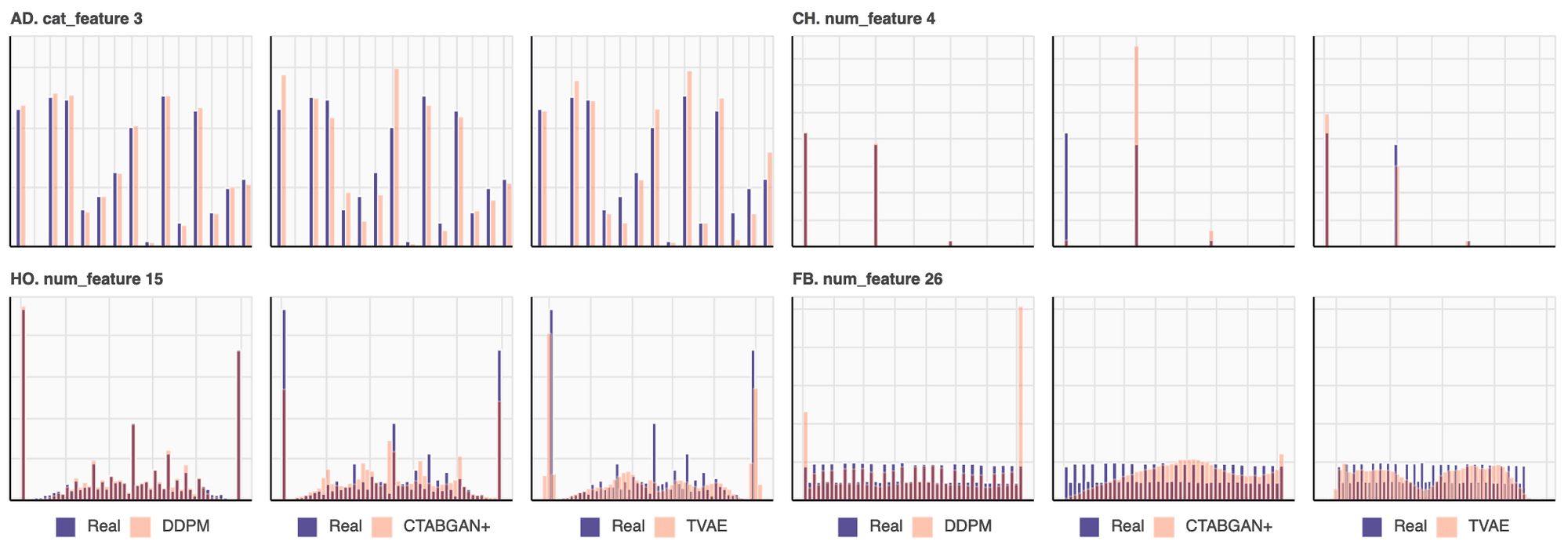
Main takeaway from privacy evaluation:
The table shows that TabDDPM is superior in privacy. This experiment confirms that TabDDPM’s synthetic samples, while providing high ML efficiency, are also more appropriate for privacy-concerned scenarios.
Additional thoughts
- Strong classification/regression models, like CatBoost, are crucial for ML efficiency evaluation. In our paper [1], we show that evaluation using average score across multiple weak models (this method was popular in prior works) may be misleading.
- It is important to note that DCR is not a perfect privacy metric, and it is hard to come up with a new one. However, we still consider TabDDPM a step forward in high-quality and private generation.