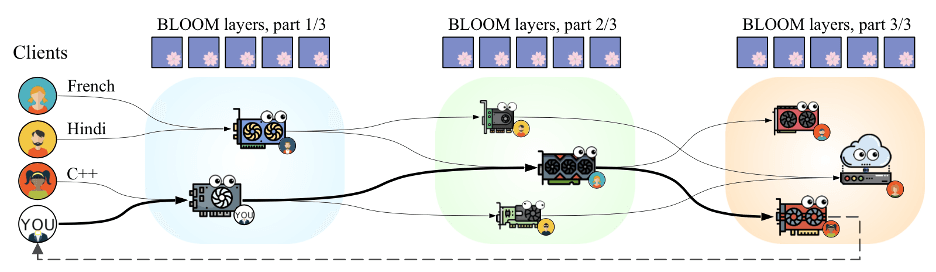
Since 2020, we have seen large language models (LLMs) like GPT-3 rapidly improve their capabilities, sometimes gaining emergent properties such as in-context learning. In 2022 and early 2023, many open-access alternatives to proprietary LLMs were released: notable examples of this trend include BLOOM, OPT, LLaMA, as well as YaLM developed by Yandex. However, using these models with high performance is still an engineering challenge: models with over 170 billion parameters need over 340 gigabytes of GPU memory to be stored in FP16 precision, which exceeds the limits of any single accelerator.
From a user perspective, an easy solution is to use APIs, where the model is hosted by an external provider charging for requests to this LLM. While this approach does not require expertise in model serving, it is also the least flexible one: API maintainers usually do not allow inspecting the internal states of the neural network, which can be helpful for its analysis. Also, the model itself might be phased out of service by the provider, which makes it especially difficult to conduct reproducible research using such APIs.
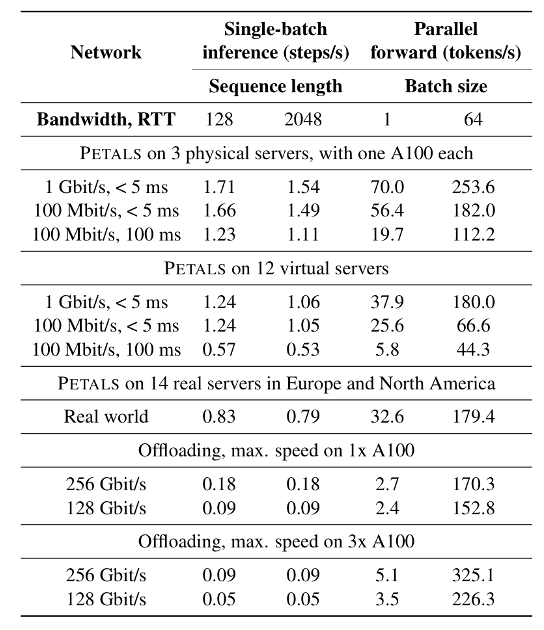
In contrast, offloading the neural network weights to larger local storage (such as RAM or SSD) grants full control over the model. Even if your personal computer has enough memory, the latency of this approach is significantly higher: generating a single token with BLOOM-176B, offloading will take more than 5 seconds because of the data transfer bottleneck. Such a delay might be acceptable for batch processing but not for interactive applications: hence, we need something that is transparent yet can be fast enough.