Papers accepted to NeurIPS 2025
Five papers by the Yandex Research team (shown in bold below) and our collaborators have been accepted for publication at the Conference on Neural Information Processing Systems (NeurIPS 2025).
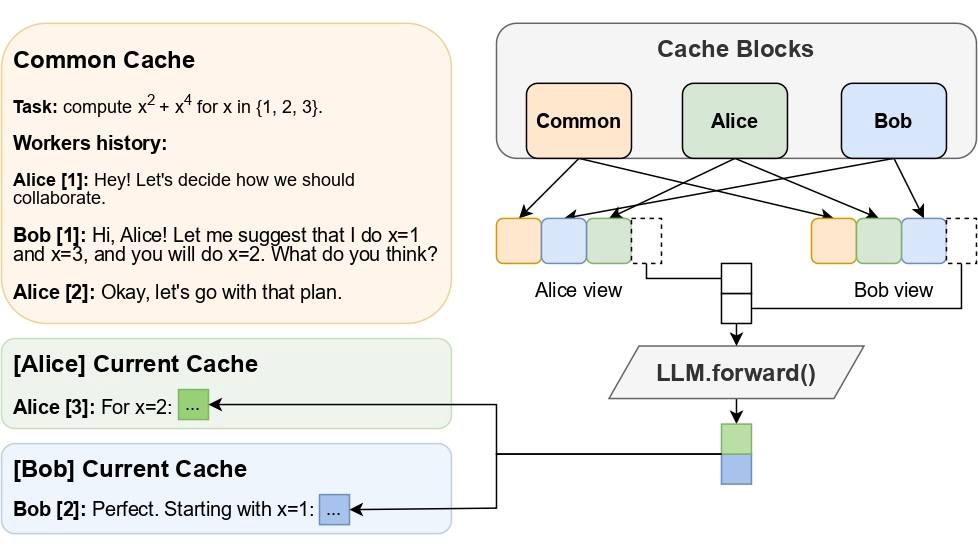
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention by Gleb Rodionov, Roman Garipov, Alina Shutova, George Yakushev, Erik Schultheis, Vage Egiazarian*, Anton Sinitsin, Denis Kuznedelev, Dan Alistarh
In this paper, we propose a new approach to accelerate LLM inference by running multiple LLM “workers” in parallel and allowing them to synchronize via a concurrently-updated attention cache; this is implemented via Hogwild! Inference, a parallel LLM inference engine that uses Rotary Position Embeddings (RoPE) to avoid recomputation and improve hardware utilization, enabling LLM instances to develop their own collaboration strategy without additional fine-tuning. The paper has been accepted at NeurIPS 2025 as a spotlight.
AutoJudge: Judge Decoding Without Manual Annotation by Roman Garipov, Fedor Velikonivtsev, Ivan Ermakov, Ruslan Svirschevski, Vage Egiazarian*, Max Ryabinin
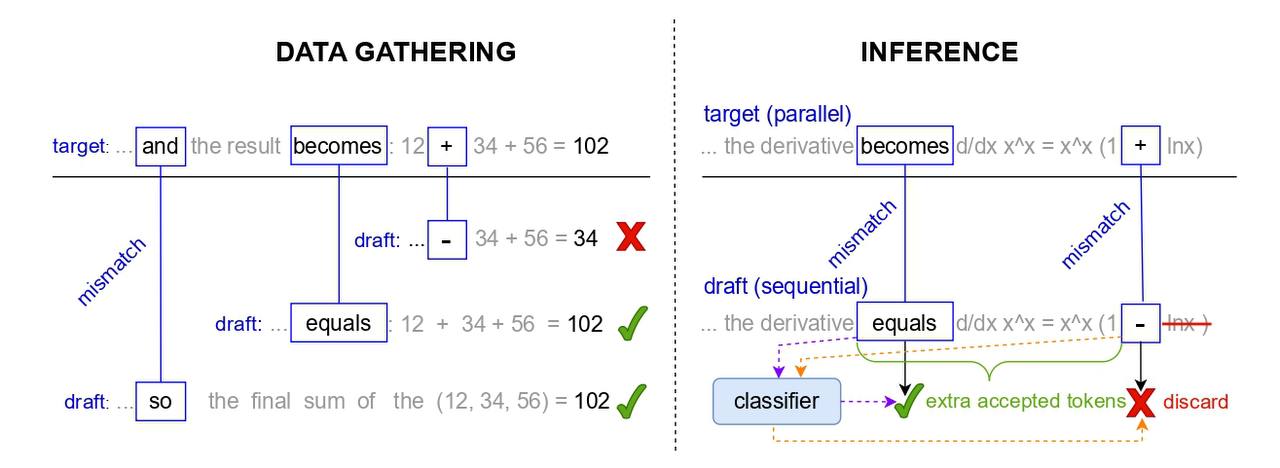
In this paper, we introduce AutoJudge, a method that accelerates large language model (LLM) inference through task-specific lossy speculative decoding. Instead of matching the target model’s output distribution token by token, AutoJudge identifies which generated tokens affect downstream quality, relaxing the distribution-matching requirement so that unimportant tokens can be safely accepted.
Our approach employs a semi-greedy search to determine which mismatches between the draft and target models should be corrected to preserve quality and which can be skipped. We then train a lightweight classifier based on LLM embeddings to predict, at inference time, which mismatching tokens can be accepted without compromising the final answer quality.
AutoJudge can accept up to 40 draft tokens per verification cycle with only a slight accuracy drop, achieving 1.5–2× speedup, and is easy to integrate into existing LLM inference frameworks.
*Work done during employment at Yandex.
GraphLand: Evaluating Graph Machine Learning Models on Diverse Industrial Data by Gleb Bazhenov, Oleg Platonov and Liudmila Prokhorenkova
Current graph ML benchmarks suffer from limited scope and practical relevance. To address this issue, we introduce GraphLand — a benchmark of 14 diverse graph datasets for node property prediction from various industrial applications. GraphLand enables evaluating graph ML models on a wide range of graphs under different realistic settings. We find that graph neural networks achieve strong results on GraphLand datasets, showing their strong potential for use in industrial applications, while currently available general-purpose graph foundation models achieve very weak results and fail to compete with other methods.
Alchemist: Turning Public Text-to-Image Data into Generative Gold by Valerii Startsev, Alexander Ustyuzhanin, Alexey Kirillov, Dmitry Baranchuk, Sergey Kastryulin

This paper introduces a novel methodology for creating general-purpose supervised fine-tuning (SFT) datasets for text-to-image (T2I) models by using a pre-trained generative model to estimate high-impact training samples; the methodology was used to create and release Alchemist, a compact (3,350 samples) SFT dataset that substantially improves the generative quality of five public T2I models while preserving diversity and style. The weights of the fine-tuned models are also publicly available.
Results of the Big ANN: NeurIPS’23 competition by Harsha Vardhan Simhadri, Martin Aumüller, Amir Ingber, Matthijs Douze, George Williams, Magdalen Dobson Manohar, Dmitry Baranchuk, Edo Liberty, Frank Liu, Ben Landrum, Mazin Karjikar, Laxman Dhulipala, Meng Chen, Yue Chen, Rui Ma, Kai Zhang, Yuzheng Cai, Jiayang Shi, Yizhuo Chen, Weiguo Zheng, Zihao Wan, Jie Yin, Ben Huang
The 2023 Big ANN Challenge at NeurIPS 2023 focused on advancing ANN search by addressing complex variants such as filtered search, out-of-distribution data, sparse and streaming variants; participants’ solutions demonstrated significant improvements in search accuracy and efficiency compared to industry standards. The paper summarizes the competition tracks, datasets, evaluation metrics, and approaches of top-performing submissions, offering insights into current advancements and future directions in ANN search.