
Papers accepted to NeurIPS 2024
Eight papers by the Yandex Research team (shown in bold below) and our collaborators have been accepted for publication at the Conference on Neural Information Processing Systems (NeurIPS 2024).
SpecExec: Massively Parallel Speculative Decoding for Interactive LLM Inference on Consumer Devices by Ruslan Svirschevski, Avner May, Zhuoming Chen, Beidi Chen, Zhihao Jia, Max Ryabinin
We propose SpecExec (Speculative Execution), a simple parallel decoding method that can generate up to 20 tokens per target model iteration for popular LLM families. It utilizes the high spikiness of the token probabilities distribution in modern LLMs and a high degree of alignment between model output probabilities. SpecExec takes the most probable tokens continuation from the draft model to build a “cache” tree for the target model, which then gets validated in a single pass. Using SpecExec, we demonstrate inference of 50B+ parameter LLMs on consumer GPUs with RAM offloading at 4-6 tokens per second with 4-bit quantization or 2-3 tokens per second with 16-bit weights.
PV-Tuning: Beyond Straight-Through Estimation for Extreme LLM Compression by Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik
We study the problem of “extreme” compression of large language models to 1-2 bits per parameter. At this compression level, even modern LLM quantization algorithms (AQLM, QuIP#, etc.) can no longer cope with the quantization errors and the models often break down completely. This happens because, whenever a layer is quantized, it produces a slightly different output that then gets fed into the next layer and the error increases further, eventually spiraling out of control. Since quantizing layers to 1-2 bits will always lead to high quantization error, the only way to deal with it is to teach the layers to compensate each other’s errors, or at least adjust to them. In this paper, we propose a specialized algorithm, called PV-Tuning, for ‘tuning’ quantized layers to work together better as a whole. This significantly improves 1-2 bit LLMs and results in the first 2-bit model quantization that makes practical sense.
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding by Zhuoming Chen, Avner May, Ruslan Svirschevski, Yuhsun Huang, Max Ryabinin, Zhihao Jia, Beidi Chen
This paper introduces Sequoia, a scalable, robust and hardware-aware algorithm for speculative decoding. To attain better scalability, Sequoia introduces a dynamic programming algorithm to find the optimal tree structure for the speculated tokens. To achieve robust speculative performance, Sequoia uses a novel sampling and verification method that outperforms prior work across different decoding temperatures. Finally, Sequoia introduces a hardware-aware tree optimizer that maximizes speculative performance by automatically selecting the token tree size and depth for a given hardware platform. Evaluation shows that Sequoia improves the decoding speed of Llama2-7B, Llama2-13B, and Vicuna-33B on an A100 by up to 4.04×, 3.73×, and 2.27×. For offloading setting on L40, Sequoia achieves as low as 0.56 s/token for exact Llama2-70B inference latency, which is 9.96× on our optimized offloading system (5.6 s/token), 9.7× than DeepSpeed-Zero-Inference, 19.5× than Huggingface Accelerate.
Challenges of Generating Structurally Diverse Graphs by Fedor Velikonivtsev, Mikhail Mironov, Liudmila Prokhorenkova
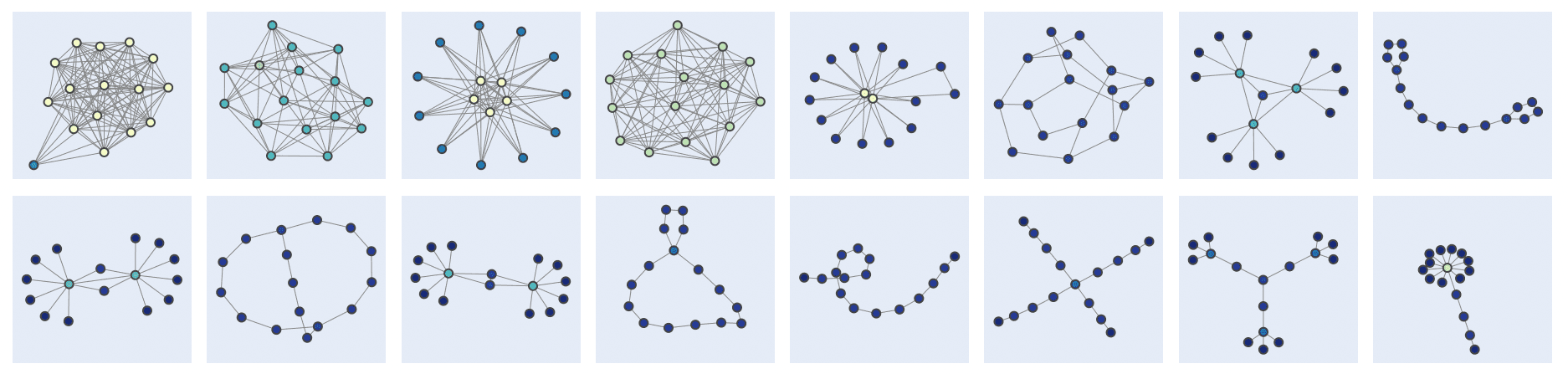
We address the problem of generating graphs that are structurally diverse. First, we discuss how to define diversity for a set of graphs, why this task is non-trivial, and how one can choose a proper diversity measure. Then, for a given diversity measure, we propose and compare several algorithms optimizing it: we consider approaches based on standard random graph models, local graph optimization, genetic algorithms, and neural generative models. We show that it is possible to significantly improve diversity over basic random graph generators and generate structurally diverse graphs (as shown in the figure above) even when starting from simple Erdős–Rényi graphs.
Invertible Consistency Distillation for Text-Guided Image Editing in Around 7 Steps by Nikita Starodubcev, Mikhail Khoroshikh, Artem Babenko, Dmitry Baranchuk

Diffusion distillation represents a highly promising direction for achieving faithful text-to-image generation in a few sampling steps. However, despite recent successes, existing distilled models still do not provide the full spectrum of diffusion abilities, such as real image inversion, which enables many precise image manipulation methods. This work aims to enrich distilled text-to-image diffusion models with the ability to effectively encode real images into their latent space. To this end, we introduce invertible Consistency Distillation (iCD), a generalized consistency distillation framework that facilitates both high-quality image synthesis and accurate image encoding in only 3−4 inference steps. Though the inversion problem for text-to-image diffusion models gets exacerbated by high classifier-free guidance scales, we notice that dynamic guidance significantly reduces reconstruction errors without noticeable degradation in generation performance. As a result, we demonstrate that iCD equipped with dynamic guidance may serve as a highly effective tool for zero-shot text-guided image editing, competing with more expensive state-of-the-art alternatives.
Rethinking Optimal Transport in Offline Reinforcement Learning by Arip Asadulaev, Rostislav Korst, Alexander Korotin, Vage Egiazarian, Andrey Filchenkov, Evgeny Burnaev
In this paper we introduced a novel algorithm for offline reinforcement learning that uses optimal transport. Typically, in offline reinforcement learning, the data is provided by various experts and some of them can be sub-optimal. To extract an efficient policy, it is necessary to stitch the best behaviors from the dataset. To address this problem, we rethink offline reinforcement learning as an optimal transportation problem. And based on this, we present an algorithm that aims to find a policy that maps states to a partial distribution of the best expert actions for each given state. We evaluate the performance of our algorithm on continuous control problems from the D4RL suite and demonstrate improvements over existing methods.
The Iterative Optimal Brain Surgeon: Faster Sparse Recovery by Leveraging Second-Order Information by Diyuan Wu, Ionut-Vlad Modoranu, Mher Safaryan, Denis Kuznedelev, Dan Alistarh

Learning curve with standard Gaussian prior.
Optimal Brain Surgeon (OBS) framework, which leverages loss curvature information to make better pruning decisions, and Iterative Hard Thresholding (IHT), that inspired wealth of sparse recovery algorithms, are two established and versatile tools for neural network sparsification. However, so far a connection between them was absent. In this work, we propose new sparse recovery algorithms inspired by the OBS framework that come with theoretical guarantees and strong practical performance. Specifically, we show than one can leverage curvature information in OBS-like fashion upon the projection step of classic iterative sparse recovery algorithms such as IHT. We show for the first time that this leads both to improved convergence bounds under standard assumptions.
Lower Bounds and Optimal Algorithms for Non-Smooth Convex Decentralized Optimization over Time-Varying Networks by Dmitry Kovalev, Ekaterina Borodich, Alexander Gasnikov, Dmitrii Feoktistov
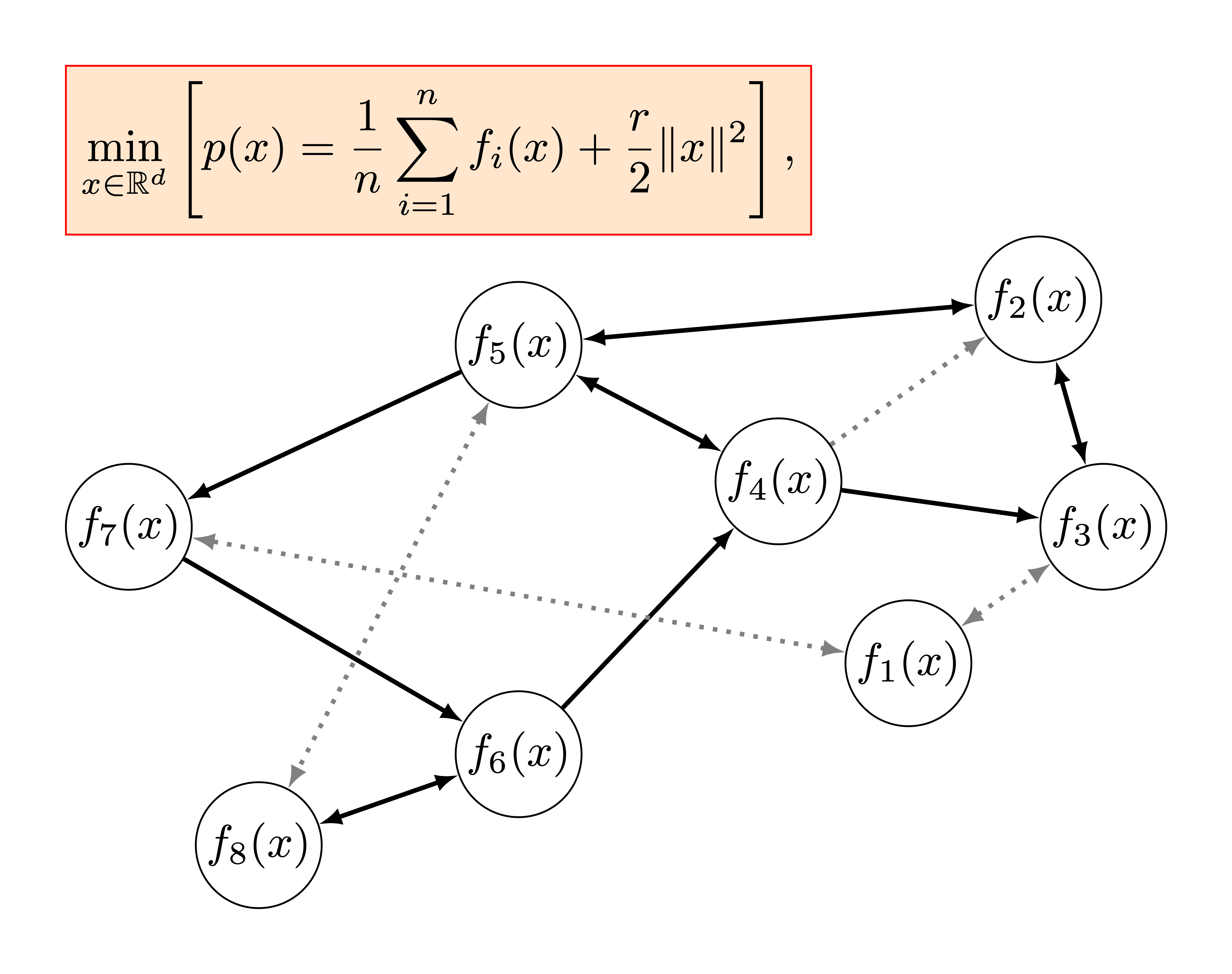
We revisit the problem of minimizing the sum of convex functions stored in a decentralized manner across compute nodes connected through a communication network. We focus on the fundamental and most challenging, yet largely understudied, setting where the objective functions are non-smooth and the links in the communication network are allowed to change over time. The contributions of our paper are twofold: (i) we establish the first lower bounds on the number of decentralized communication rounds and local gradient computations required by any first-order optimization algorithm to solve the problem; (ii) we develop the first optimal algorithm that matches these lower bounds and provides a vast theoretical performance improvement compared to the existing state of the art.