Papers accepted to NeurIPS 2022
Five papers have been accepted for publication at the Conference on Neural Information Processing Systems (NeurIPS 2022).
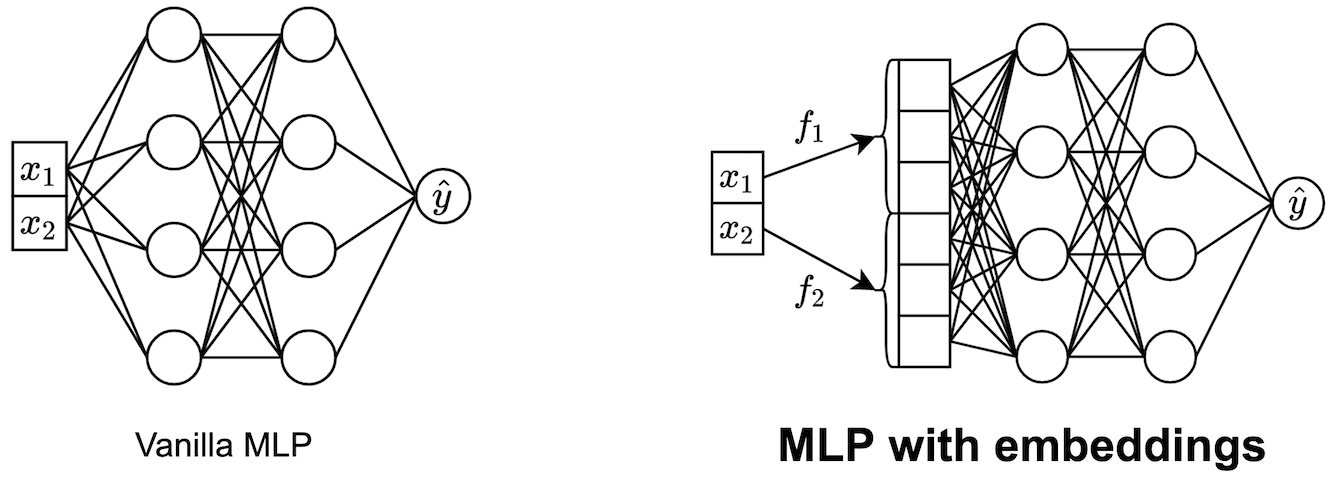
On Embeddings for Numerical Features in Tabular Deep Learning by Yury Gorishniy, Ivan Rubachev, Artem Babenko
In tabular data problems, there are many kinds of features, such as categorical, ordinal or numerical. In this work, we show that transforming numerical scalar features to vectors before passing them to a backbone can lead to significant improvements for deep learning models on tabular data problems. This may seem counterintuitive: why would one represent a scalar value with a vector? However, the results of the extensive experiments indicate that this technique is an important and underexplored degree of freedom in tabular deep learning.
Distributed Methods with Compressed Communication for Solving Variational Inequalities, with Theoretical Guarantees by Aleksandr Beznosikov, Peter Richtárik, Michael Diskin, Max Ryabinin, Alexander Gasnikov
In this paper, we present the first theoretically grounded distributed methods for solving variational inequalities and saddle point problems using compressed communication. Our theory and methods allow for the use of both unbiased (such as random choices of coordinates) and contractive (such as geedy choices of coordinates) compressors. New algorithms support bidirectional compressions and also can be modified for stochastic settings with batches and for federated learning with partial participation of clients.
Decentralized Local Stochastic Extra-Gradient for Variational Inequalities by Aleksandr Beznosikov, Pavel Dvurechensky, Anastasia Koloskova, Valentin Samokhin, Sebastian U. Stich, Alexander Gasnikov
We consider distributed stochastic variational inequalities with the problem data that is heterogeneous and distributed across many devices. We make a very general assumption on the computational network that, in particular, covers the settings of fully decentralized calculations with time-varying networks and centralized topologies commonly used in Federated Learning. Moreover, multiple local updates on the workers can be made for reducing the communication frequency between the workers. We extend the stochastic extragradient method to this general setting and theoretically analyze its convergence rate.
Optimal Algorithms for Decentralized Stochastic Variational Inequalities by Dmitry Kovalev, Aleksandr Beznosikov, Abdurakhmon Sadiev, Michael Persiianov, Peter Richtárik, Alexander Gasnikov
We consider decentralized stochastic (sum-type) variational inequalities over fixed and time-varying networks. We present lower complexity bounds for communication and local iterations and construct optimal algorithms that match these lower bounds. Our algorithms are the best among the available literature not only in the decentralized stochastic case but also in the decentralized deterministic and non-distributed stochastic cases.
Optimal Gradient Sliding and its Application to Distributed Optimization Under Similarity by Dmitry Kovalev, Aleksandr Beznosikov, Ekaterina Borodich, Alexander Gasnikov, Gesualdo Scutari
We study structured convex optimization problems, with additive objective $r:=p+q$. For such a class of problems, we propose an inexact accelerated gradient sliding method that can achieve optimal complexity of gradient calls of $p$ and $q$. We then apply the proposed method to solve distributed optimization problems over master-worker architectures, under agents' function similarity, due to statistical data similarity or otherwise. The distributed algorithm achieves for the first time lower complexity bounds on both communication and local gradient calls, with the former having being a long-standing open problem.